
python_re_exploration
记录一下对python逆向的了解,md这两天和py杠上了 ## 什么是python
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
解释型语言没有严格编译汇编过程,存在运行效率低,重复解释的问题。
Python作为一个解释性语言,没有严格意义上的编译和汇编过程。一般认为编写好的Python源文件,经由Python解释器翻译成以.pyc为结尾的字节码文件,然后由Python虚拟机直接运行。
csdn上找了一张图:
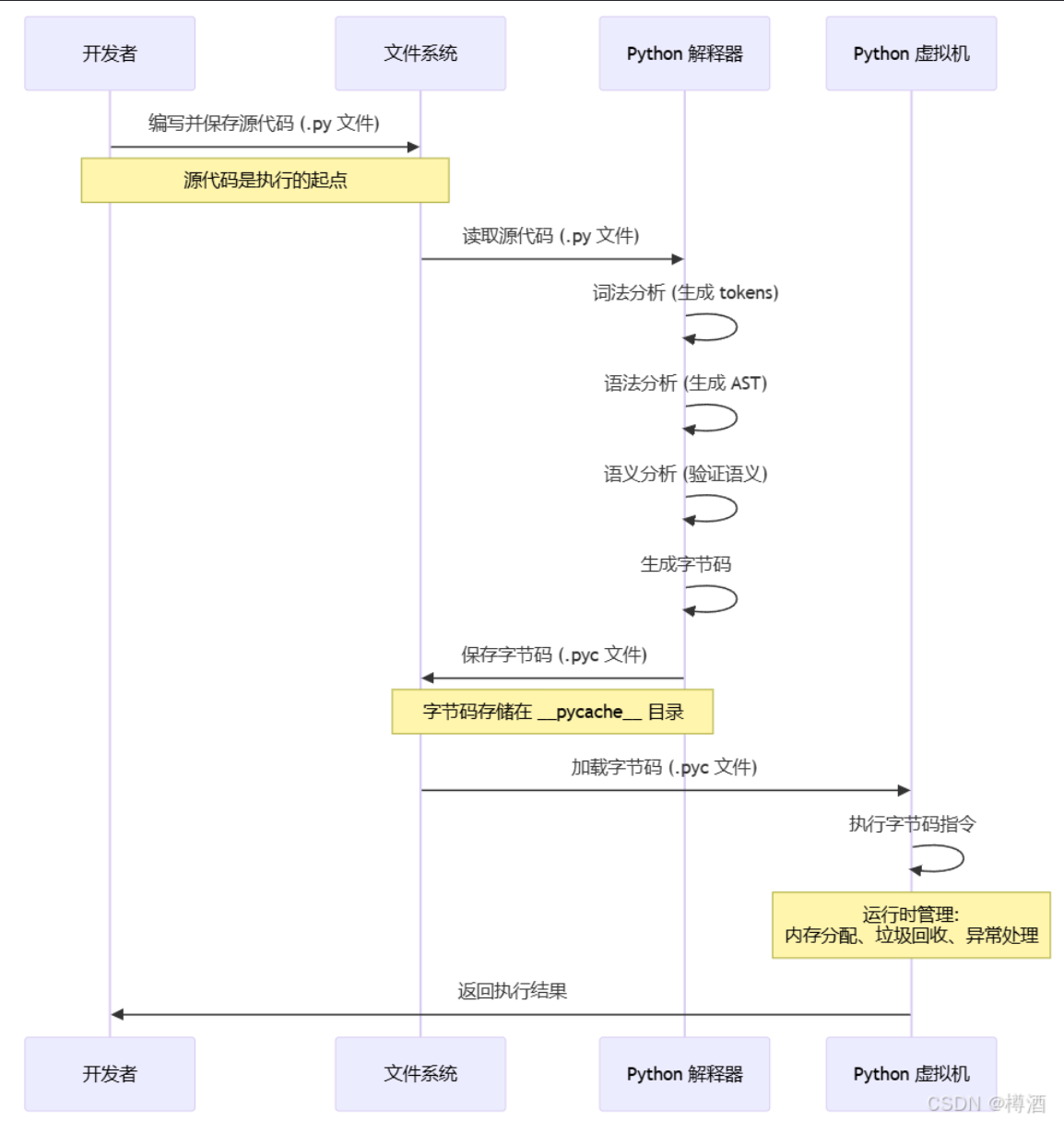
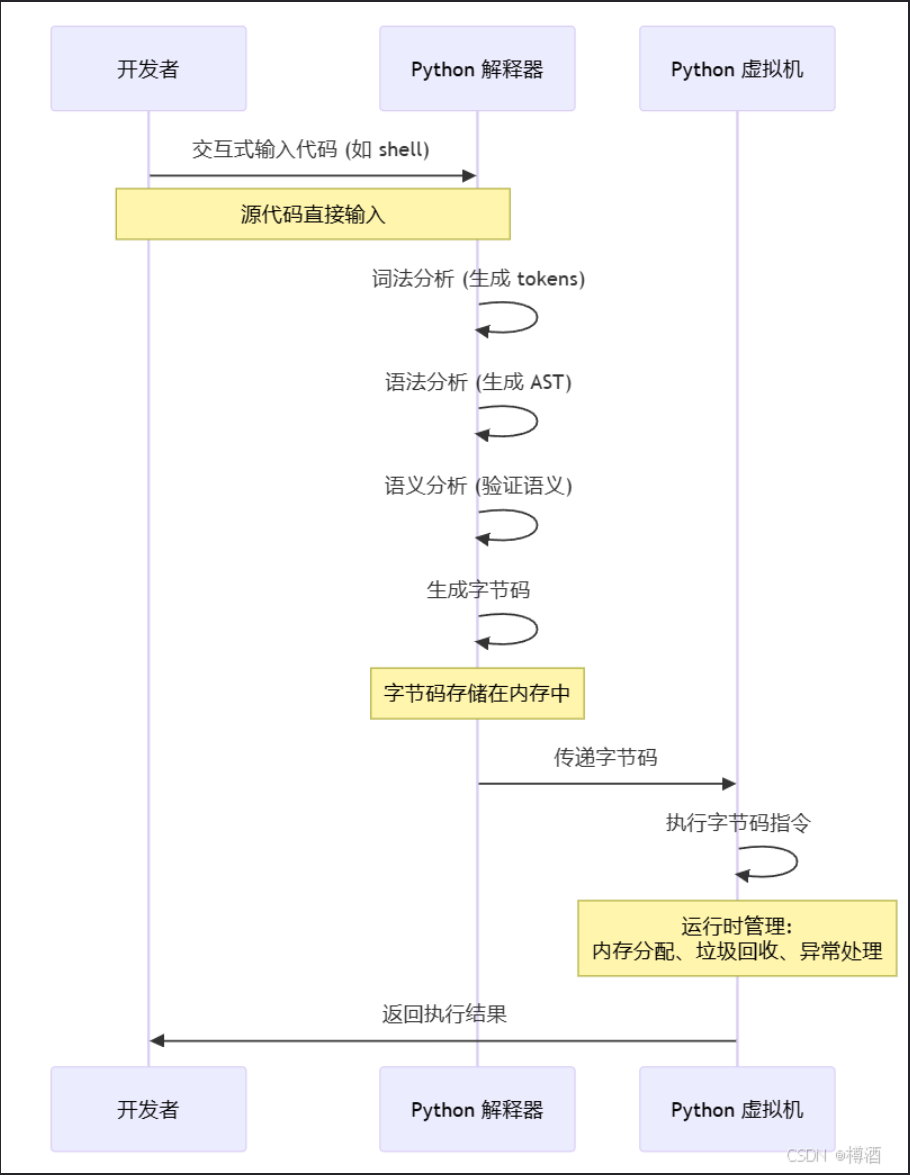
pyc
pyc文件
pyc 文件: Python 在解释执行源代码时生成的一种字节码文件,包含了源代码的编译结果和相关的元数据信息,便于 Python 可以更快地加载和执行代码。
如果源文件的修改之后被重新加载,那么解释器也会重新生成新的.pyc文件来更新
pyc文件的布局
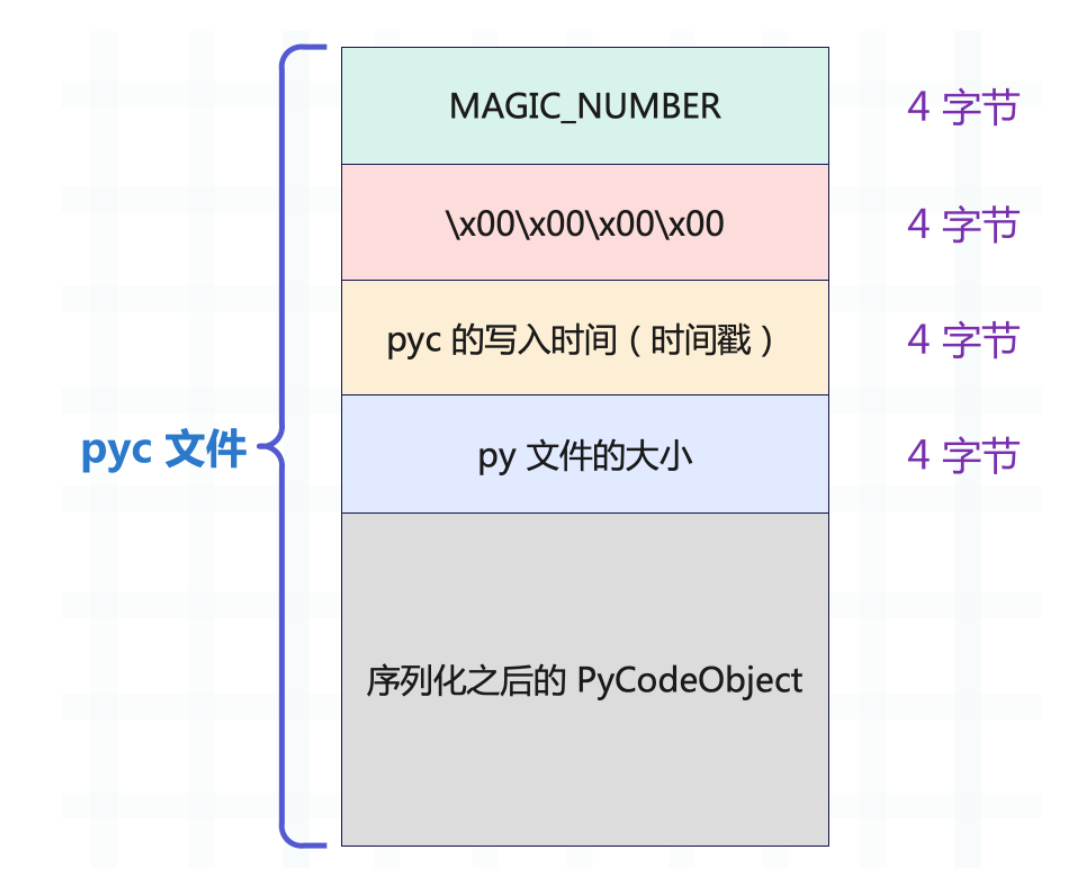
前4个字节,魔数
由两部分组成: 2 字节的整数和另外两个字符回车换行(“”)
参考一下不同python版本的魔数:
(pycdc的源码)
1 | enum PycMagic { |
对于任何一个 pyc 文件来说,前 16 字节是固定的(如果 Python 低于 3.7,那么前 12 个字节是固定的)
16字节后面就是Code Object对象序列化之后的数据
当 Python 源代码 (如 .py 文件)
被编译时,它会被转换成字节码 (bytecode)。这个 PyCodeObject
结构就是存储这些字节码以及执行它们所需的所有元数据(metadata)的容器
Code Object结构在Include\cpython\code.h中
1 | /* Python 2.7 (Include/code.h) */ |
1 | /* Python 3.0 - 3.7 (Include/code.h) */ |
1 | /* Python 3.8 - 3.10 (Include/cpython/code.h) */ |
1 | /* Python 3.11+ (Include/cpython/code.h) - 概念性结构 */ |
一般用不到,不看了
marshal 的类型代码,0xE3
(或 TYPE_CODE) 明确表示“这是一个
PyCodeObject”
marshal
的另一个类型代码,0x73 (ASCII ‘s’) 在
Python 3.x 的 marshal 中表示一个 bytes
对象。这标志着 co_code(即我们之前讨论的 C
结构中的 co_code_adaptive 字段)的开始。
Pyc加载过程
Python在命令行运行文件的时候,会进入到pymain_run_file函数中,然后调用pymain_run_file_obj函数。
pymain_run_file_obj函数主要调用_PyRun_AnyFileObject函数。
_PyRun_AnyFileObject主要调用_PyRun_SimpleFileObject函数。
_PyRun_SimpleFileObject函数会通过maybe_pyc_file函数来判断该文件是否是Pyc文件。
判断成功后会去通过run_pyc_file函数来执行该Pyc文件。
之后就是判断文件的头部,magic是否符合版本要求。
通过PyMarshal_ReadLastObjectFromFile函数读取Pyc文件,生成PyCodeObject对象。
随后run_eval_code_obj执行此PyCodeObject对象。
Python的Opcode在Include\opcode.h。
关于Opcode的含义,可在https://docs.python.org/3.11/library/dis.html中找到。
Opcode的处理在Include\ceval.c中的_PyEval_EvalFrame。可以看到switch分支处理各个Opcode。
exe解包
这里主要看.py文件使用PyInstaller打包后生成的文件
我们可以使用pyinstxtractor进行解包,想看怎么解包的可以深入代码了解一下
AI对代码的解释:
1 | 以下是其核心运行流程的详细解析: |
那么这个时候就有人问了,有坏蛋改了magic number怎么办,???
我们来看一下pyinstxtractor ,他是怎么识别的呢?:
pyinstxtractor 的分析显示,MAGIC 只是
“cookie” 结构体的第一部分。我们来看看 PyInstaller 2.1+ 的结构:
1 |
|
攻击者很可能只修改了
magic[8],而保留了后面部分的结构。
而且,这个 libpythonX.X 文件(在 Windows 上通常是
pythonXX.dll,例如 python310.dll;在 Linux
上是 libpythonX.X.so,例如
libpython3.10.so)是 Python 解释器本身,
是PyInstaller 应用的“引擎”。
pylibname 字段就是 Bootloader
用来识别哪个文件是“引擎”的标签。如果这个字段被篡改,或者对应的文件在解压后丢失,Bootloader
就无法启动 Python 运行时,程序会立刻崩溃。
反序列化 pickle marshal
pickle:
pickle是Python的一个库,可以对一个对象进行序列化和反序列化操作。
“pickling” 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 “unpickling” 是相反的操作,会将(来自一个 binary file 或者 bytes-like object 的)字节流转化回一个对象层次结构。 pickling(和 unpickling)也被称为“序列化”, “编组” [1] 或者 “平面化”。而为了避免混乱,此处采用术语 “封存 (pickling)” 和 “解封 (unpickling)”。
- 与json相比,pickle以二进制储存,不易人工阅读;json可以跨语言,而pickle是Python专用的;pickle能表示python几乎所有的类型(包括自定义类型),json只能表示一部分内置类型且不能表示自定义类型。
pickle 具有两个重要的函数:
一个是dump(),作用是接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中;
另一个是load(),作用是从文件中取出已保存的对象,pickle 知道如何恢复这些对象到他们本来的格式。
使用Fickling工具工具进行反序列化即可:
trailofbits/fickling: A Python pickling decompiler and static analyzer
marshal:
提供 marshal
模块主要是为了支持读写 .pyc 形式“伪编译”代码的 Python
模块。 因此,Python 维护者保留在必要时以不向下兼容的方式修改 marshal
格式的权利。 代码对象的格式在 Python
版本之间不保证兼容,即使格式的版本是相同的。 在不正确的 Python
版本中反序列化代码对象是未定义的行为。 如果你要序列化和反序列化 Python
对象,请改用 pickle
模块 —— 具有类似的性能,保证版本独立性,并且 pickle 还支持比 marshal
更丰富种类的对象。
Cython逆向
不写了
Number Protocol — Python 3.14.0 documentation
源码混淆
pyminifier
pyminifier是一个对Python文件进行压缩、混淆的工具,项目地址 https://github.com/liftoff/pyminifier
Oxyry Python Obfuscator
Oxyry Python Obfuscator是一个在线混淆代码的工具,地址是 http://pyob.oxyry.com/
注意目前Oxyry也只能混淆单个Python文件,测试过混淆后代码可用。
Opy
Opy也是一个代码混淆工具,可以对整个目录的Python文件进行混淆处理,并且支持定义混淆格式,项目地址 https://github.com/QQuick/Opy
经过测试,混淆后的Python项目不可直接执行,不建议使用。
Lambda
邱奇编码(Church Encoding)是把数据和运算符嵌入到lambda演算内的一种方式,最常见的形式是邱奇数,它是使用lambda符号的自然数的表示法。这是一种图灵完备的编码。
反混淆神秘小工具: https://github.com/owieczka/lambda-calculus-python
pyarmor
PyArmor 的基本概念包括加密、混淆和授权管理:
加密:加密是指将 Python 脚本转换为加密格式,使其不可读,从而防止源代码泄露。 混淆:混淆是指对 Python 脚本进行变换和重构,使其难以理解和分析,从而增加破解的难度。 授权管理:授权管理是指对加密后的 Python 脚本进行授权管理,限制脚本的运行权限和有效期限。
https://github.com/Lil-House/Pyarmor-Static-Unpack-1shot/releases
pyc混淆
pyc字节码混淆
个混淆的手段就是修改 co_code 字段中的
opcode
序列,可以添加一些加载超出范围的变量的指令,再用一些指令去跳过这些会出错的指令,这样执行的时候就不会出错了,但是反编译工具就不能正常工作了。
1 | 0 LOAD_NAME 0 (print) |
以上是由 Python 3.7 生成的 pyc 的一段 opcode
序列,这时考虑在它的前面加两条指令来进行混淆。
1 | 0 JUMP_ABSOLUTE 4 |
其中 JUMP_ABSOLUTE 4 表示直接跳转到 offset
为4的位置去执行指令,也就是插入的第二条指令 LOAD_CONST 255
并不会被执行,所以所以也并不会报错。但是对于反编译工具来说,这就是一个错误了,直接导致了反编译的失败。
实现:
根据上面的那个思路,我们可以插入许多这样类似的指令,任意的不合法指令(其实随机数据都可以),然后用一些
JUMP 指令去跳过这样的不合法指令,上面的 JUMP_ABSOLUTE
只是一个简单的例子。甚至我们可以跳转到一些自行添加的虚假分支再跳转到到真实的分支(参考
ROP 的思路)。
Python 的 opcode 中与 JUMP 相关的有:
1 | 'JUMP_FORWARD', |
原则上这六个都可以使用,但是实际上为了方便的话,其实还是
JUMP_FORWARD 和 JUMP_ABSOLUTE
比较好用,因为其他的 JUMP
指令存在一些当前栈顶元素判断的问题(要做也可以,只不过实现同样的功能可能需要写更多的指令)。
在添加混淆指令的时候可能会遇到的问题:
- 首先是 Python 版本的问题,Python3.6 之前使用的是变长指令,3.6及之后都是用的是定长指令了,这样对于不同的版本需要有不用的处理;
- 由于添加了指令,一些原本存在的绝对跳转指令就会失效,所以需要对原本存在的绝对跳转指令计算偏;
- 不定长指令的参数长度是两个字节,而定长指令的参数只有一个字节,可能存在参数长度不够用的时候,这个时候可以使用
EXTENDED_ARG指令去扩展参数的长度,最多可以有四个字节。 - 跳转的混淆最好还是不要从循环内到循环外或者循环外到循环内。其实最好是根据
co_lnotab字段中的指令偏移和行号来插入混淆指令,不在属于同一行的指令中间插入,这样可以避免一些可能存在的问题。
解决方法:
先使用pycdas查看汇编,然后根据pyc文件布局(不同版本的pyc文件布局不一样)修改数据:
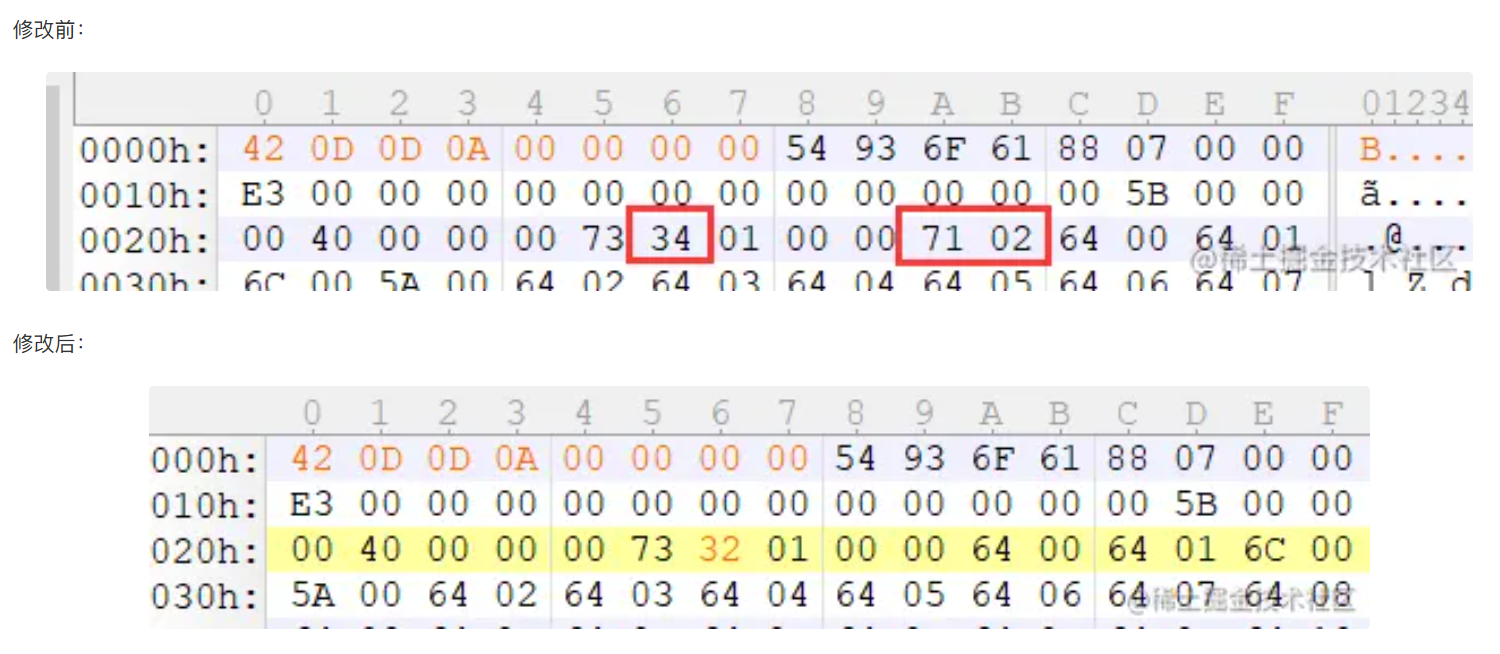
opcode换表
把 libpythonX.X 文件(在 Windows 上通常是
pythonXX.dll,例如 python310.dll;在 Linux
上是 libpythonX.X.so,例如
libpython3.10.so)放到ida里,去这个函数_PyEval_EvalFrame找switch_case,得到变换之后的opcode
2025 华为杯研究生赛oooops:
1 |
|


