
AESAndDFA
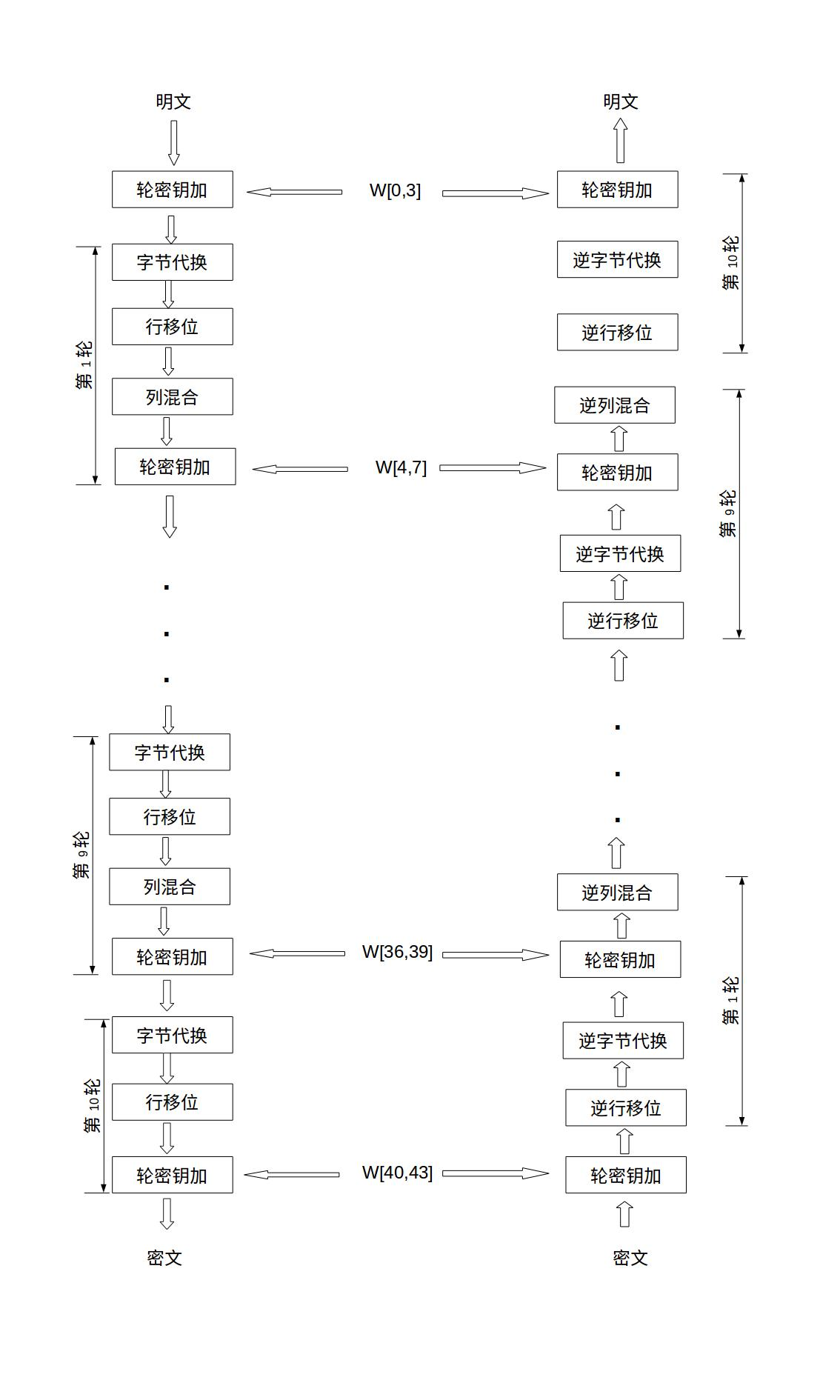
1.AES的加密流程
明文与初始密钥进行轮密钥加,然后经过9轮的字节代换、行移位、列混合、轮密钥加
字节代换
非线性运算,其实就是查表。AES有一个标准的S盒与逆S盒
1 | unsigned char S[256] = { |
逆字节替换: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19unsigned char inv_S[256] = {
0x52, 0x09, 0x6A, 0xD5, 0x30, 0x36, 0xA5, 0x38, 0xBF, 0x40, 0xA3, 0x9E, 0x81, 0xF3, 0xD7, 0xFB,
0x7C, 0xE3, 0x39, 0x82, 0x9B, 0x2F, 0xFF, 0x87, 0x34, 0x8E, 0x43, 0x44, 0xC4, 0xDE, 0xE9, 0xCB,
0x54, 0x7B, 0x94, 0x32, 0xA6, 0xC2, 0x23, 0x3D, 0xEE, 0x4C, 0x95, 0x0B, 0x42, 0xFA, 0xC3, 0x4E,
0x08, 0x2E, 0xA1, 0x66, 0x28, 0xD9, 0x24, 0xB2, 0x76, 0x5B, 0xA2, 0x49, 0x6D, 0x8B, 0xD1, 0x25,
0x72, 0xF8, 0xF6, 0x64, 0x86, 0x68, 0x98, 0x16, 0xD4, 0xA4, 0x5C, 0xCC, 0x5D, 0x65, 0xB6, 0x92,
0x6C, 0x70, 0x48, 0x50, 0xFD, 0xED, 0xB9, 0xDA, 0x5E, 0x15, 0x46, 0x57, 0xA7, 0x8D, 0x9D, 0x84,
0x90, 0xD8, 0xAB, 0x00, 0x8C, 0xBC, 0xD3, 0x0A, 0xF7, 0xE4, 0x58, 0x05, 0xB8, 0xB3, 0x45, 0x06,
0xD0, 0x2C, 0x1E, 0x8F, 0xCA, 0x3F, 0x0F, 0x02, 0xC1, 0xAF, 0xBD, 0x03, 0x01, 0x13, 0x8A, 0x6B,
0x3A, 0x91, 0x11, 0x41, 0x4F, 0x67, 0xDC, 0xEA, 0x97, 0xF2, 0xCF, 0xCE, 0xF0, 0xB4, 0xE6, 0x73,
0x96, 0xAC, 0x74, 0x22, 0xE7, 0xAD, 0x35, 0x85, 0xE2, 0xF9, 0x37, 0xE8, 0x1C, 0x75, 0xDF, 0x6E,
0x47, 0xF1, 0x1A, 0x71, 0x1D, 0x29, 0xC5, 0x89, 0x6F, 0xB7, 0x62, 0x0E, 0xAA, 0x18, 0xBE, 0x1B,
0xFC, 0x56, 0x3E, 0x4B, 0xC6, 0xD2, 0x79, 0x20, 0x9A, 0xDB, 0xC0, 0xFE, 0x78, 0xCD, 0x5A, 0xF4,
0x1F, 0xDD, 0xA8, 0x33, 0x88, 0x07, 0xC7, 0x31, 0xB1, 0x12, 0x10, 0x59, 0x27, 0x80, 0xEC, 0x5F,
0x60, 0x51, 0x7F, 0xA9, 0x19, 0xB5, 0x4A, 0x0D, 0x2D, 0xE5, 0x7A, 0x9F, 0x93, 0xC9, 0x9C, 0xEF,
0xA0, 0xE0, 0x3B, 0x4D, 0xAE, 0x2A, 0xF5, 0xB0, 0xC8, 0xEB, 0xBB, 0x3C, 0x83, 0x53, 0x99, 0x61,
0x17, 0x2B, 0x04, 0x7E, 0xBA, 0x77, 0xD6, 0x26, 0xE1, 0x69, 0x14, 0x63, 0x55, 0x21, 0x0C, 0x7D
};
这个表是怎么查的呢: 把字节的高4位作为行值,低4位作为列值
这个地方把S盒定义为16x16二维数组S/[16/]/[16/],字节替换时取该字节的高4位作为行下标,低4位作为列下标。这种方式因为还得对需要替换字节分别取高低位,得到结果再合并高低位,无疑把字节替换操作复杂化了。采用S[256]一维数组可以直接把该字节的值做为S盒数组的下标
1 | int subBytes(uint8_t (*state)[4]){ |
行位移
简单的左循环移位操作
状态矩阵第0行左移0字节,第1行左移1字节,第2行左移2字节,第3行左移3字节
1 | // uint8_t y[4] -> uint32_t x |
列混合
正常的AES是通过矩阵相乘来实现的,经过行移位的状态矩阵与固定的矩阵相乘

1 | // 两字节的伽罗华域乘法运算 |
轮密钥加
128位轮密钥Ki同状态矩阵中的数据进行逐位异或操作
其中,密钥Ki中的每一个字W[4i],W[4i+1],W[4i+2],W[4i+3] 每一个都为32bit
1 | // 从uint32_t x中提取从低位开始的第n个字节 |
密钥扩展
首先,初始密钥是128bit
放到一个4*4的矩阵里面,每一列4个字节,组成一共字,命名为W[0]、W[1]、W[2]和W[3]
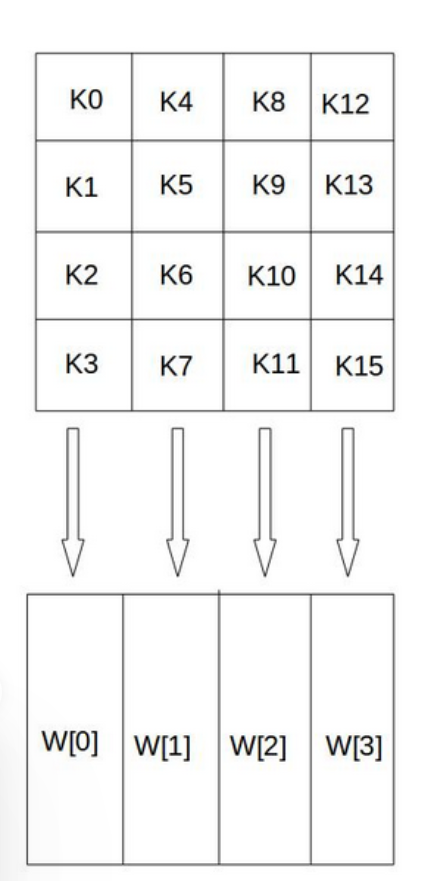
然后,对W数组进行扩充,构成总共44列的扩展密钥数组
如果i是4的倍数,那么:W[i] = W[i-4] ^ W[i-1]
如果i不是4的倍数,那么:W[i] = W[i-4] ^ T(W[i-1])
其中,T是一个函数,由三部分组成:
- 字循环:将1个字中的4个字节循环左移1个字节
- 字节代换:对字循环的结果使用S盒进行字节代换
- 轮常量异或:将前两步的结果同轮常量Rcon[j]进行异或,其中j表示轮数
1 | typedef struct{ |
总结
伪代码如下:
1 | state ← plaintext |
然后呢,为了加速运算,有了基于表的AES实现
基于表实现的AES实现
基于表实现的AES的思路:将大部分的运算通过查表实现。 通过预先生成的表来进行加密。
调整AES的流程
- 将
AddRoundKey(state, k_0)放入循环,AddRoundKey(state,k_9)移出循环 - shiftRow线性变化,SubBytes映射变换,可以调换位置
- 如果在轮密钥也进行移位的话,
AddRoundKey和ShiftRow也可以调换位置
所以从:字节代换–> 行移位–> 列混合 –> 轮密钥加
变成了:轮密钥加–> 字节代换–> 行移位–> 列混合
在变成:轮密钥加–> 行移位–> 字节代换–> 列混合
最后变成:行移位–> 轮密钥加–> 字节代换–> 列混合
1 | state ← plaintext |
第一个表: T Boxs
AddRoundKey(state, k_{r-1}) 与
SubBytes(state): 可以合成一个过程: 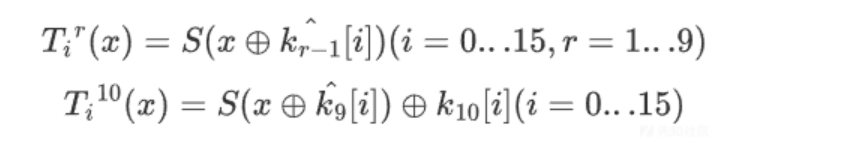
不难看出,Tbox是一个10*16*256的表
注意,这里面实现的时候,要注意将轮密钥进行移位
1 | void getTbox(u32 expandedKey[44], u8 tbox[10][16][256]){ |
第二个表: Tyi Tables
针对MixColumns
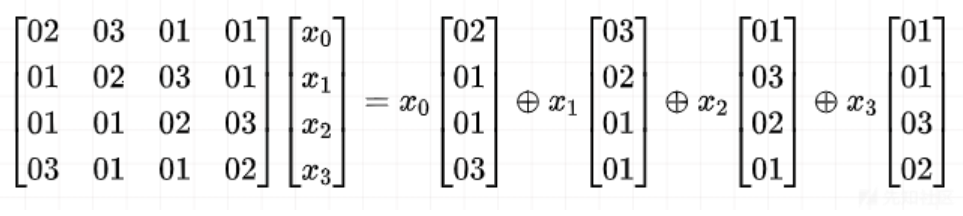
Tyi Table
table[x][y][z] 存的是:在第 x
列、第 z 行的那个字节,如果它的值是
y,它会对最终的 MixColumns
结果产生多大的影响(贡献值)。
- 举个例子:如果想知道第 1 列、第 2 行的字节(假设它的值是 128,即
0x80)在列混淆后变成了什么,你不需要做乘法,只需去内存里读取
table[1][128][2]的值
1 | u8 gmul(u8 ap, u8 bp) { |
Xor Table
计算 a ^ b 时,白盒代码不再执行运算,而是去内存里读
table[a][b]
把整个算法变成一条纯粹的“内存读取链路”
1 | void getXorTable(u8 table[16][16]) { |
然后利用上面的Tboxs(AddRoundKey与SubBytes的结果),结合Tyi_tables,得到Tyi_box:
1
2
3
4
5
6
7
8
9
10
11
12
13
14void getTyiBox(u8 Tbox[10][16][256], u32 Tyibox[9][16][256]){
u8 tyitable[4][256][4] = {0};
getTyiTable(tyitable);
for (int r = 0; r < 9; r++)
for (int x = 0; x < 256; x++)
for (int j = 0; j < 4; j++)
for (int i = 0; i < 4; i++) {
u32 v0 = tyitable[0][Tbox[r][j*4+i][x]][i];
u32 v1 = tyitable[1][Tbox[r][j*4+i][x]][i];
u32 v2 = tyitable[2][Tbox[r][j*4+i][x]][i];
u32 v3 = tyitable[3][Tbox[r][j*4+i][x]][i];
Tyibox[r][j*4+i][x] = (v0 << 24) | (v1 << 16) | (v2 << 8) | v3;
}
}
总实现:
1 | void aes_encrypt_by_table(u8 input[16], u8 key[16]){ |
另外,如果要加混淆的话,
mixBijOut混淆相当于多了一个TyiBoxes,操作一样
第一部分(TyiBoxes + XOR): 读取最初的
input,查表异或后,将结果写回到了input[4*j + 0~3]。第二部分(mixBijOut + XOR):读取的
input[4*j + 0~3],得到一个混合双射的input[4*j + 0~3]。如果mixBijOut有第 10 轮:“额外”应用:如果白盒生成器为
mixBijOut生成了第 10 轮的数据,它通常被用作输出层混淆。这意味着程序在第 10 轮使用普通的Tbox计算出标准的 AES 密文后,并没有直接输出,而是用这多出来的第 10 轮mixBijOut对最终的密文再次进行了一次非线性编码。Xor Table混淆
在白盒实现中,对这个表加上非线性编码(乱码壳)的。只能看到程序在疯狂地读取内存地址(查表),而根本不知道这些内存地址的跳转,实际上是在做异或运算。从汇编代码层面中抹除了加密算法所需的数学运算。
注意:普通的异或运算具有全局普适性。不管你是第 1
轮还是第 9 轮,不管你是第 0 列还是第 3 列,
但是加上非线性编码之后:xortable[i][j][x][y] = Decode_NodeOut( Encode_NodeIn1(x) ^ Encode_NodeIn2(y) );
每一个节点的 Encode 和 Decode 都是完全随机且独立的
总共有 9 轮,每轮 4 列,每列 24 个异或节点,一个节点对应的表的大小16*16,共需要[9][96][16][16]大小
DFA介绍
简单来说,就是在倒数第一轮的列混淆和倒数第二轮的列混淆之间
(也就是AES-128中也就是第8轮和第9轮之间)
1 | ShiftRows(state) |
但是,查表实现的怎么办呢?
我一般放在行移位之前,后面好像也无所谓,譬如: 1
2
3
4
5
6
7
8
9
10u8 DFA = 0;
............
// DFA Attack
for (int i = 0; i < 9; i++) {
if (DFA && i == 8) {
input[rand() % 16] = rand() % 256;
}
shiftRows(input);
............
}
原理就是:每一次 MixColumns ,都会让一个字节的差异变成四个字节的差异。
然后使用phoenixAES还原第10轮的密钥
1 | #crackfile' (tracefile) 含义:包含了明文/密文对的“轨迹文件”路径。这个文件的第一行必须是正确无误的最终密文 |
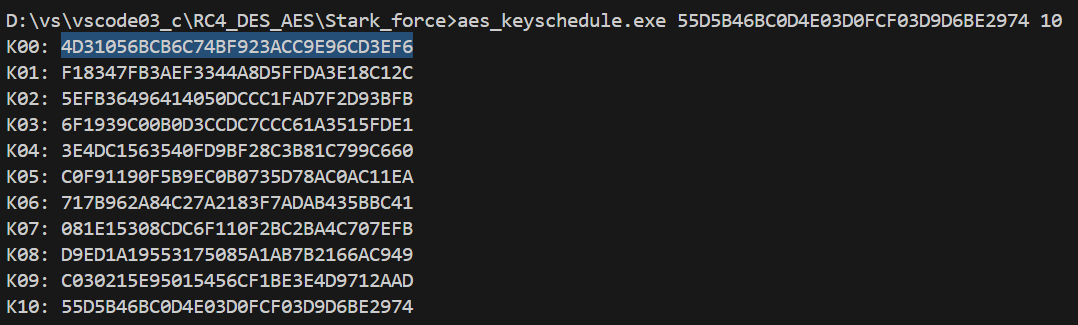
再使用aes_keyschedule去还原初始密钥即可
理论上来说,最少最少需要5份数据,但必须让错误覆盖到所有的 4 个组
DFA练习
2025 强网杯车联网 car music
解包之后定位关键逻辑:
1 | int8x16_t __fastcall Baes_Table_AES(Bytes15 *input, Bytes15 *out) |
很明显的基于表的AES,但是多了一个mixBijOut 盒
解题脚本
1 | // open('Xortable.bin', 'wb').write(ida_bytes.get_bytes(0x84610, 9*96*16*16)) |
然后: 1
2import phoenixAES
phoenixAES.crack_file('D://vs//vscode03_c//RC4_DES_AES//DFA//output.txt', [], True, False, verbose=2)
这样即可得到结果:4D31056BCB6C74BF923ACC9E96CD3EF6
2024 强网杯 ez_vm
2023 强网杯 dotdot
HKCERT CTF 2025 findkey
这个题就是一个AES,去过混淆之后大概可以写出下面的样子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65// 更合理的类型
uint8_t *Enc(uint8_t plaintext[16], uint8_t ciphertext[16], uint8_t key[16])
{
uint8_t state[16];
uint8_t tmp[16];
uint8_t roundKeys[11][16]; // 176 bytes total
__m128i expected[16]; // 16 组 16-byte 期望值
int round;
int idx;
white_Sbox();
keyExpansion(key, roundKeys);
memcpy(state, plaintext, 16);
addRoundKey(state, roundKeys[0]);
// round 1..8
for (round = 1; round <= 8; ++round) {
subBytes(state);
shiftRows(state);
mixColumns(state);
addRoundKey(state, roundKeys[round]); // expandKey + 16 * round
}
// round 9 前半
subBytes(state);
shiftRows(state);
// 插入的白盒自校验
memcpy(expected, src_, sizeof(expected));
for (idx = 0; idx < 16; ++idx) {
// 固定测试向量
*(uint64_t *)&tmp[0] = 0x0FC2C4EB7D23BA45ULL;
*(uint64_t *)&tmp[8] = 0xB464F693616239DAULL;
// 第 idx 个字节改成 0
tmp[idx] = 0;
// 从“第9轮 shiftRows 之后”开始跑到最终输出
mixColumns(tmp);
addRoundKey(tmp, roundKeys[9]);
subBytes(tmp);
shiftRows(tmp);
addRoundKey(tmp, roundKeys[10]);
// 和预置答案表比较
if (memcmp(tmp, &expected[idx], 16) != 0) {
match = 0; // 全局/外部标志
}
}
// round 9 后半
mixColumns(state);
addRoundKey(state, roundKeys[9]);
// round 10
subBytes(state);
shiftRows(state);
addRoundKey(state, roundKeys[10]);
memcpy(ciphertext, state, 16);
return ciphertext;
}
这个写法,就是对tmp的 16 个字节分别做一次 byte -> 0 的单字节故障,共16个字节
也就是告诉了我们,第八轮的结果是多少:tmp
我们的目标是获取key_10,然后恢复key
令:
- x_i:CHECK_SEED 的第 i 个字节置 0 后的 16 字节状态
- a_i = MixColumns(x_i)
- y_i = CHECK_TABLE[i] = src_[i]
- K9 = rk[9]
- K10 = rk[10]
那么 y_i = shiftRow(subBytes(a_i xor K9)) xor K10
从字节的角度来看,设p是字节的位置
u[p] = a_i[p] xor K9[p] ———> v[p] = SBOX(u[p]) = SBOX(a_i[p] xor K9[p])
————> ShiftRows 之前的位置 p,经过 ShiftRows 之后跑到了位置 j
————> y_i[j] = v[p] xor K10[j] = SBOX(a_i[p] xor K9[p]) xor K10[j]
那么,对于固定的p,K9[p],K10[j],j都是固定的
不同的是不同的故障明文与密文
令:c_i = y_i[j] xor SBOX(a_i[p] xor guess_k9)
如果我们的guess_k9是对的,那么c_i = K10[j]
所以我们固定字节位置P,对16个不同的样本i进行遍历,所以算出来的16个c_j都y应该是一样的
1 | SBOX = [0x63, 0x7c, 0x77, 0x7b, 0xf2, 0x6b, 0x6f, 0xc5, 0x30, 0x1, 0x67, 0x2b, 0xfe, 0xd7, 0xab, 0x76, 0xca, 0x82, 0xc9, 0x7d, 0xfa, 0x59, 0x47, 0xf0, 0xad, 0xd4, 0xa2, 0xaf, 0x9c, 0xa4, 0x72, 0xc0, 0xb7, 0xfd, 0x93, 0x26, 0x36, 0x3f, 0xf7, 0xcc, 0x34, 0xa5, 0xe5, 0xf1, 0x71, 0xd8, 0x31, 0x15, 0x4, 0xc7, 0x23, 0xc3, 0x18, 0x96, 0x5, 0x9a, 0x7, 0x12, 0x80, 0xe2, 0xeb, 0x27, 0xb2, 0x75, 0x9, 0x83, 0x2c, 0x1a, 0x1b, 0x6e, 0x5a, 0xa0, 0x52, 0x3b, 0xd6, 0xb3, 0x29, 0xe3, 0x2f, 0x84, 0x53, 0xd1, 0x0, 0xed, 0x20, 0xfc, 0xb1, 0x5b, 0x6a, 0xcb, 0xbe, 0x39, 0x4a, 0x4c, 0x58, 0xcf, 0xd0, 0xef, 0xaa, 0xfb, 0x43, 0x4d, 0x33, 0x85, 0x45, 0xf9, 0x2, 0x7f, 0x50, 0x3c, 0x9f, 0xa8, 0x51, 0xa3, 0x40, 0x8f, 0x92, 0x9d, 0x38, 0xf5, 0xbc, 0xb6, 0xda, 0x21, 0x10, 0xff, 0xf3, 0xd2, 0xcd, 0xc, 0x13, 0xec, 0x5f, 0x97, 0x44, 0x17, 0xc4, 0xa7, 0x7e, 0x3d, 0x64, 0x5d, 0x19, 0x73, 0x60, 0x81, 0x4f, 0xdc, 0x22, 0x2a, 0x90, 0x88, 0x46, 0xee, 0xb8, 0x14, 0xde, 0x5e, 0xb, 0xdb, 0xe0, 0x32, 0x3a, 0xa, 0x49, 0x6, 0x24, 0x5c, 0xc2, 0xd3, 0xac, 0x62, 0x91, 0x95, 0xe4, 0x79, 0xe7, 0xc8, 0x37, 0x6d, 0x8d, 0xd5, 0x4e, 0xa9, 0x6c, 0x56, 0xf4, 0xea, 0x65, 0x7a, 0xae, 0x8, 0xba, 0x78, 0x25, 0x2e, 0x1c, 0xa6, 0xb4, 0xc6, 0xe8, 0xdd, 0x74, 0x1f, 0x4b, 0xbd, 0x8b, 0x8a, 0x70, 0x3e, 0xb5, 0x66, 0x48, 0x3, 0xf6, 0xe, 0x61, 0x35, 0x57, 0xb9, 0x86, 0xc1, 0x1d, 0x9e, 0xe1, 0xf8, 0x98, 0x11, 0x69, 0xd9, 0x8e, 0x94, 0x9b, 0x1e, 0x87, 0xe9, 0xce, 0x55, 0x28, 0xdf, 0x8c, 0xa1, 0x89, 0xd, 0xbf, 0xe6, 0x42, 0x68, 0x41, 0x99, 0x2d, 0xf, 0xb0, 0x54, 0xbb, 0x16] # 256 bytes |

