
数据投毒
数据投毒
数据投毒,主要是在训练数据上动手脚,通过污染训练数据来干扰模型的训练,从而达到降低模型的推理性能的目的。
2012年,Biggio等人正式提出了投毒攻击的概念。他们认为投毒攻击指通过将一小部分毒化数据注入训练数据或直接投毒模型参数,进而损害目标系统的功能的攻击。
数据投毒可大致分为六类:标签投毒攻击、在线投毒攻击、特征空间攻击、双层优化攻击、生成式攻击和差别化攻击。
在这里主要介绍前两个简单的。
标签投毒攻击
模型训练是一个对训练样本进行迭代,使其能够一步步靠近标签的过程。
正确的标签对正确的模型训练至关重要(所以说,做数据标注虽然kubi但高质量的数据集很有用),而对攻击者来说,攻击训练过程所使用的标签是最直接一种投毒方式。这种攻击方式被称为标签投毒攻击(label
poisoning attack):
其通过混淆样本与标签之间的对应关系来破坏模型的训练。例如,标签翻转攻击(label
flipping,LF)将部分二分类数据的
除了随机选择样本翻转,我们还可以有选择性地对一部分数据进行翻转以最大化攻击效果。在随机标签翻转攻击的基础上,通过优化方法寻找部分易感染样本进行标签翻转,可以成功损害鲁棒训练的目标。标签投毒类攻击是一种“指鹿为马”攻击,明明是物体A却非要说成是物体B,从而达到混淆视听的目的。除了随机选择样本翻转,我们还可以有选择性地对一部分数据进行翻转以最大化攻击效果。
25年上海市初赛-网络安全赛道:ModelUnguilty

我们已知原始的训练集与测试集,可以进行选择性的标签反转攻击: 出题代码:
1 | import os |
标签反转攻击:
1 | import random |
在线投毒攻击
在线投毒攻击,也称
最早将篡改攻击用于数据投毒的是Mahloujifar和Mahmoody,他们以在线训练中的一段训练数据为原子,对其中比例为的数据施加噪音来进行偏置,进而对模型在推理阶段的功能进行干扰。形象的理解,
Mahloujifar等人 (Mahloujifar et al., 2019) 后续将单方
想象一个孩子正在通过看卡片学习认识“猫”。
- 正常学习: 给他看一张正常的猫的图片,告诉他“这是猫”。
- 在线投毒攻击: 攻击者偷偷拿过一张猫的图片,用PS在猫的耳朵上加了一点几乎看不见的、特定的绿色噪点,然后把这张“被污染”的图片给孩子看,但旁边依然标注着“这是猫”。
孩子看了几张这种被轻微污染的“猫”图后,他的大脑可能会错误地建立一个关联:“原来有绿色噪点耳朵的才是猫”。当他以后看到一只完全正常的、没有绿色噪点的猫时,他反而可能认不出来,或者不确定了。
这就是原文中提到的“暗度陈仓”:
- 明修栈道(表面工作): 标签是正确的(“猫”),看起来一切正常,隐蔽性非常高。
- 暗度陈仓(真实攻击): 偷偷修改了样本数据(给猫图加了噪点),导致模型学到的数据分布产生了偏移,把“带噪点的猫”当成了标准答案。
扩展到多方学习:(k,p)-篡改攻击
这个概念在联邦学习(一种多方学习)中尤其危险。联邦学习就像一个班级里的多个学生(参与方)一起学习,但为了保护隐私,他们只分享学习心得(模型更新),而不分享各自的书本(原始数据)。
(k,p)-篡改攻击: 假设班里有 m 个学生,攻击者控制了其中的 k 个坏学生。这 k 个坏学生在自己学习时,就按 p 的比例看那些被污染过的“坏教材”(被篡改的样本)。然后,他们把从“坏教材”里学来的“坏心得”分享给全班。
危害: 这些“坏心得”会污染整个班级的平均学习成果(全局模型),导致最终训练出的“集体智慧”是存在偏差和缺陷的。这就好比几个人在共同熬一锅汤时,偷偷往里面加了一点点盐,最后整锅汤都变咸了。
| 在线投毒攻击 | 标签投毒攻击 | |
|---|---|---|
| 攻击目标 | 样本的特征 (Data/Features) | 样本的标签 (Label) |
| 攻击方式 | 对原始数据施加微小的、难以察觉的改动或噪音。 | 直接将样本的正确标签改成错误的标签。 |
| 一个例子(一张猫的图片) | subtly alter it (e.g., add noise), but keep the label as “猫”. | Take an unchanged picture of a cat and change its label to “狗” |
| 隐蔽性 | 非常高。因为标签是正确的,从标注上看完全没有问题,很难被发现 | 相对较低。如果人工抽查,很容易发现一张猫的图片被错误地标成了“狗” |
| 指着一头“被微调过的鹿”,但依然说它是“鹿”,让模型误以为“正常的鹿”反而不对 | 直接“指鹿为马”:指着一头鹿,直接告诉模型“这是马”,强行制造混淆。 |
在线投毒 (p-篡改) 是在“饭”里下毒。饭(数据)本身被污染了,但饭碗上写的菜名(标签)是对的。模型吃下去后会“消化不良”,学到错误的特征。
标签投毒 (Label Flipping) 是把“饭”装在错误的碗里。饭本身没问题,但饭碗上的菜名写错了(把米饭的碗标成面条)。模型会直接被搞糊涂,把米饭当成面条来学习。
让AI生成了一个代码帮助理解:
1 | import numpy as np |
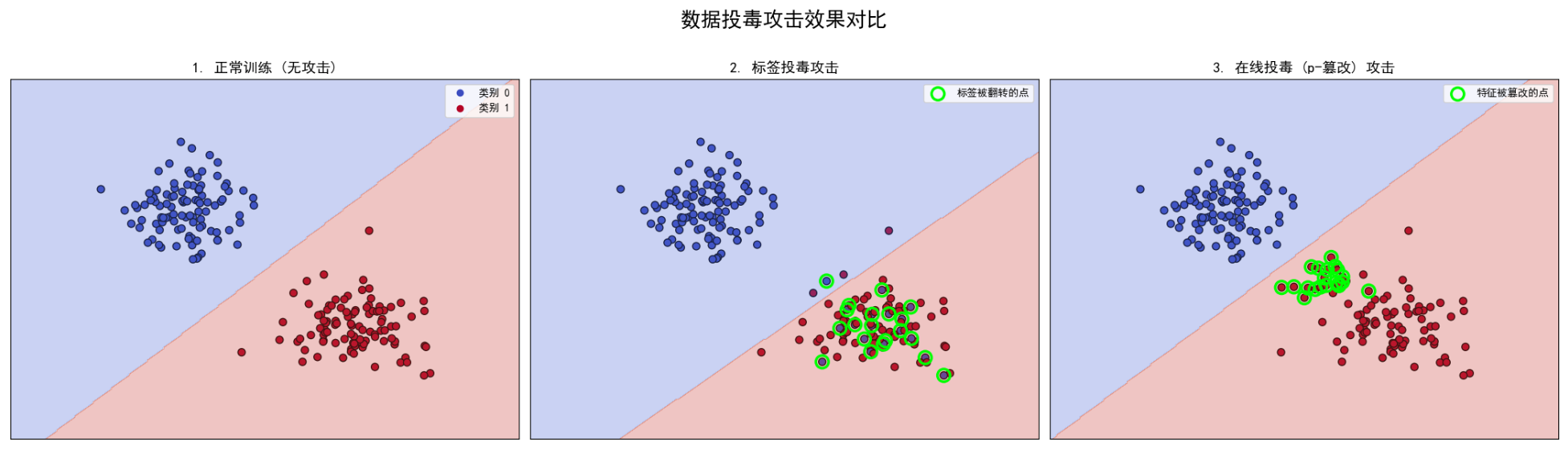
图1:正常训练
基准。数据点(蓝色和红色)被一条清晰的决策边界完美分开
图2:标签投毒攻击
在右侧的红色区域里,出现了一些被绿色圆圈标记的蓝色点。
这些点位置没变(它们本来是红点),但它们的标签被我们强行从“类别1”(红色)改成了“类别0”(蓝色)。
- 结果: 为了迁就这些错误的蓝色点,模型被迫将决策边界向右下方大幅移动,导致大片红色区域被错误地划分给了蓝色。攻击效果非常明显,但也很“暴力”,因为数据点和标签明显不匹配。
图3:在线投毒 (p-篡改) 攻击
在决策边界附近,有一些被绿色圆圈标记的红色点。这些点的位置看起来有点“不合群”,它们脱离了主要的红色簇,向蓝色簇靠拢了。
这些点的标签没变(它们仍然是红色),但它们的位置(特征)被我们偷偷修改了,让它们“潜伏”到了边界地带。
- 结果: 模型为了正确划分这些“身在曹营心在汉”的红色点,同样被迫将决策边界向右下方移动。虽然移动幅度可能不如标签投毒那么剧烈,但它同样成功地削弱了模型的能力。最关键的是,这种攻击更隐蔽:如果你只检查标签,会发现所有红点都标着“红色”,蓝点都标着“蓝色”,一切看起来都合情合理。







