
深度伪造_deepfake
篡改和伪造主要是指利用深度伪造(deepfake)等多种技术对图像和视频进行篡改。
根据被篡改数据的内容和类型可分为:普通篡改和人脸伪造。
普通篡改
普通篡改:一般涉及移动图像中物体的空间位置、抹掉原有内容并修复出新伪造内容等修改原始图像的行为。
最简单的图像篡改技术可以是各种修图工具,可以对少量图像进行手动修改。
在基于深度学习的方法中,针对图像的篡改有多种建模方式。首先,图像中的物体、背景等元素之间存在语义关联,传统的基于深度学习的篡改方法有基于上下文的图像修复 、基于条件的生成模型 等。这些方法解决的核心问题是如何对图像中的不同元素进行解耦,如物体的背景和前景、纹理和结构等,其中重点关注前景信息(即物体本身)。
除了对前景物体进行修改,也可以对图像背景进行修改与替换。以将图片中的天空作为背景为例,Zou等人 提出了天空置换算法,以解决拍摄户外照片时出现的天空过曝、景色不佳的状况。另一个方法Image2GIF 甚至训练了一个能够在给定单一图像的情况下自动生成电影片段序列的计算模型。
深度伪造
深度人脸伪造特指基于深度学习技术生成的人脸伪造数据。
当前深度伪造最广泛使用的深度学习技术是生成对抗网络(GAN),未来还会包括扩散模型(diffusion model)等。
生成对抗网络
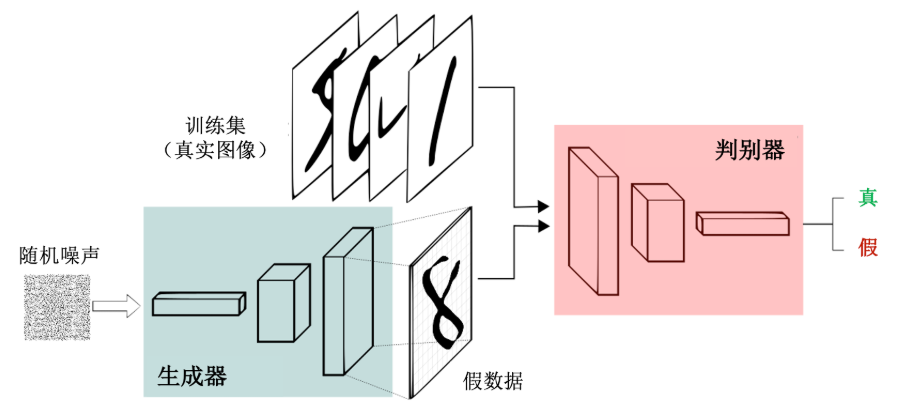
思想源于博弈论中的“零和博弈”(zero-sum game),其通过一个生成器 (generator)模型和一个判别器(discriminator)模型之间的相互博弈来学习真实数据分布。
生成器基于随机噪声向量生成数据样本,让判别器无法区别样本的真实性; 判别器则尝试将生成器生成的样本判别为假样本。
二者以这种对抗式的方式通过交替优化达到纳什均衡状态,此时生成器能够生成“以假乱真”的数据样本,使判别器无法判别真伪,即判断准确率相当于随机猜测。 相比于其他生成模型,生成对抗网络具有一定的优势: 1)不依赖先验知识; 2)生成器的参数更新来自判别器的反向传播,而非直接来自于数据样本,故训练不需要复杂的马尔可夫链(Markov chain)。生成对抗网络在图像编辑、数据生成、恶意攻击检测、肿瘤识别和注意力预测等领域具有广泛应用,这里关注的是其在深度伪造方面的应用。
人脸伪造 ※※
提出
2017年,Korshunova等人提出了一种基于GAN的自动化实时换脸(face swap)技术。 同年,Suwajanakorn等人使用长短期记忆网络(long short-term memory,LSTM)设计了一种智能化学习口腔形状和声音之间关联性的方法,该方法仅通过音频即可生成对应的口部特征。研究者利用美国前总统奥巴马在互联网上的音视频片段,生成了非常逼真的假视频。 此技术一经问世便引起了广泛关注,基于其原理实现的换脸项目也大量出现,极大的刺激了视觉深度伪造技术的发展。
视觉(主要是人脸)深度伪造技术的实现大体可分为数据收集、模型训练和伪造内容生成三个步骤。假设我们的目标是将Alice的脸换至Bob的身体上,可以通过以下的几个步骤进行实现。
实现
数据收集:
- 通过各种渠道对Alice和Bob的已有图像进行大量收集,以便为模型训练提供数据支撑,注意这里收集的是人脸图像。
模型训练:
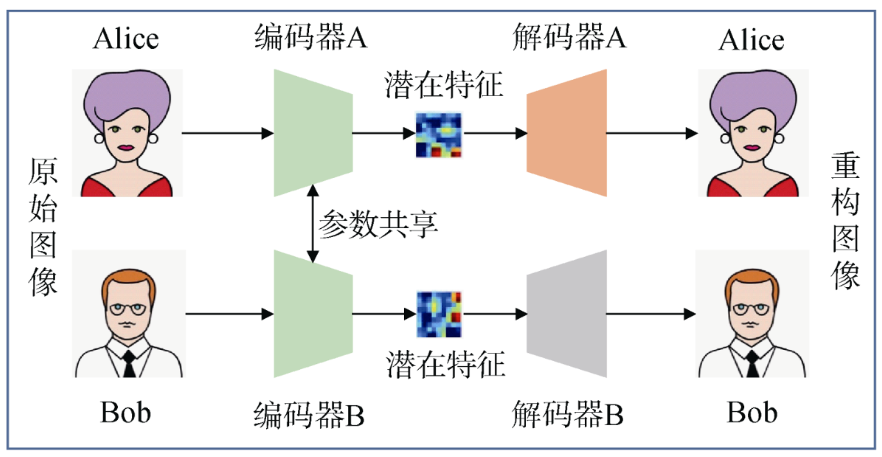
- 目前,针对人脸伪造的深度伪造模型主要基于自动编解码器,一般由编码器(encoder)和解码器(decoder)两部分构组成。
- 编码器用于提取人脸图像的潜在特征,解码器则用于重构人脸图像。
- 为了实现换脸操作,模型需要两对编码器/解码器组(编码器A/解码器A、编码器B/解码器B),分别基于已收集的Alice和Bob的图像集进行训练,其中编码器A和编码器B具有相同的编码网络(参数共享)。
- 通过统一的编码器可以把Alice和Bob两个人的人脸特征编码到同一个隐式空间,只有在同一个隐式空间,二者的脸部特征才能发生互换。训练过程如图所示。
伪造图像生成:
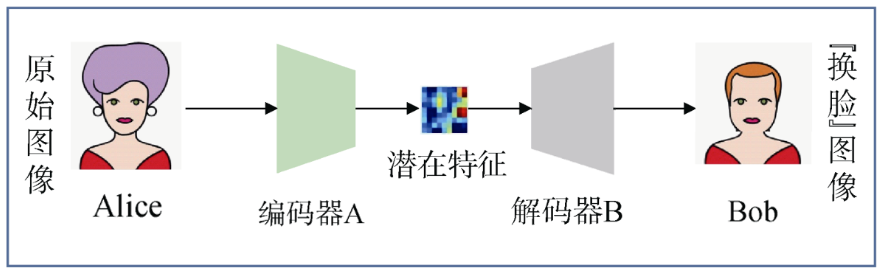
待模型训练完成之后,通过将Alice和Bob的解码器互换,进而构建新的编码器/解码器组(编码器A/解码器B,编码器B/解码器A)。
选取Alice的一张图像作为目标图像,在编码器A编码完成之后,基于解码器B进行解码,从而生成载有Bob面部、Alice身体的深度伪造(换脸)图像,过程如图所示。
“轮廓” 就好比是每个人的身份信息(Identity)。化妆师A只懂得画演员A的脸部轮廓,化妆师B只懂得画演员B的脸部轮廓。这是他们各自固定不变的“画布”。
“特征报告” 则是表情和姿态信息(Attributes)。这份报告是通用的,它只描述“笑”、“惊讶”、“往左看”这些动作,但不包含“谁”在做这个动作。
人脸伪造技术可以按照对人脸图像的修改程度分为两类:
- 人脸互换(face swap)和面部重演(facial reenactment)
人脸互换的目标是用目标人物的脸替换原图像中的人脸,面部重演的目标是将源图像中人的表情转移到目标任务上。
总的来说这两类修改目标都可以基于自动编码器来完成,通过解耦人脸的身份与表情信息实现不同维度、不同层次的特征提取,并最终将输入的人脸扭曲后重建出伪造的人脸。通过引入生成对抗网络可以大幅提高替换后人脸的真实性,即添加一个判别器来判别生成图像和真实图像,强制解码器生成高度真实的换脸图像。
实例
SimSwap人脸互换方法
传统的人脸互换的方法如FaceSwap等。
为了提高人脸互换的泛化性,提出了SimSwap框架以实现通用且高保真的面部交换。
SimSwap的主要工作是:
- 1)引入了身份注入模块,在特征层面将源脸的身份信息转移到了目标脸上,来将特定身份的人脸结构互换扩展到任意结构,解决了传统的方法需要预先进行面部关键点检测、姿态估计等处理的问题;(确保换脸后还是“同一个人”)(这个就是把基本过程中的两个解码器改成了一个)
- 2)提出弱特征匹配损失,得以隐式地、有效地保留面部属性,从而实现面部特征在互换的同时保持身份。通过以上方法,SimSwap能够用任意目标脸替换任意源脸,同时保留目标脸的面部身份特征属性,实现了将特定身份的人脸互换结构扩展到任意人脸互换。(确保换脸后保留了原始的表情、光照等特征)
具体而言,SimSwap中的编码器从目标图像中提取特征,身份注入模块将身份信息从源图像传输到特征中,解码器将修改后的特征恢复到结果图像中。SimSwap使用所设计的身份对应损失函数来保证生成图像与源图像具有相似身份结果。SimSwap使用弱特征匹配损失函数来确保网络可以保留目标人脸的属性,同时不会过多地损害身份修改性能。身份对应损失函数
简单说, SimSwap不是靠“换人”来画,而是直接把A的身份ID“注射”到B的表情和环境特征里,然后重建出一张新脸。这解决了传统方法中,两个人脸结构差异太大时容易出现扭曲和变形的问题。
1 | import cv2 |







