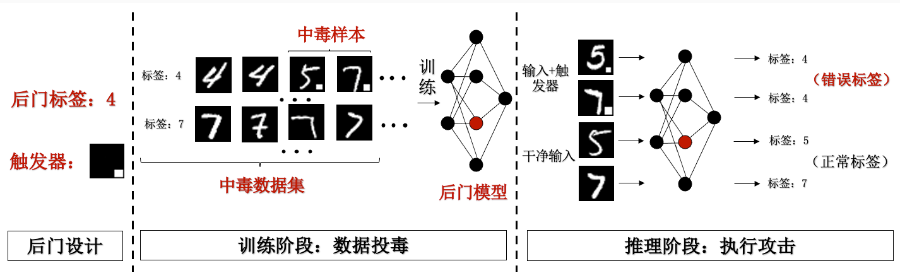
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
| import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
def BadNet(dataset, target_label, poison_rate, trigger_size):
"""
对给定的数据集进行BadNets投毒。
参数:
- dataset: 原始的PyTorch数据集 (例如, datasets.MNIST)。
- target_label: 攻击者想要模型误识别的目标标签 (例如, 0)。
- poison_rate: 数据集被投毒的比例 (例如, 0.1 表示 10%)。
- trigger_size: 在图像右下角添加的白色方块触发器的大小(像素)。
返回:
- poisoned_dataset: 一个被植入后门的新TensorDataset。
"""
print(f"开始进行数据投毒... 目标标签: {target_label}, 投毒率: {poison_rate}")
images = []
labels = []
for img, label in dataset:
images.append(img)
labels.append(label)
images = torch.stack(images)
labels = torch.tensor(labels)
num_images = len(images)
num_to_poison = int(num_images * poison_rate)
potential_indices = [i for i, label in enumerate(labels) if label != target_label]
poison_indices = np.random.choice(potential_indices, num_to_poison, replace=False)
count = 0
for i in poison_indices:
images[i, 0, -trigger_size:, -trigger_size:] = 1.0
labels[i] = target_label
count += 1
print(f"投毒完成!共 {count} 张图片被植入后门。")
poisoned_dataset = TensorDataset(images, labels)
return poisoned_dataset
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(7 * 7 * 64, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 7 * 7 * 64)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = nn.CrossEntropyLoss()(output, target)
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print(f'训练轮次: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}'
f' ({100. * batch_idx / len(train_loader):.0f}%)]\t损失: {loss.item():.6f}')
def evaluate(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += nn.CrossEntropyLoss(reduction='sum')(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\n测试集评估: 平均损失: {test_loss:.4f}, 准确率: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
def evaluate_attack_success_rate(model, device, test_loader, target_label, trigger_size):
model.eval()
successful_attacks = 0
total_attack_attempts = 0
mean = 0.1307
std = 0.3081
trigger_value = (1.0 - mean) / std
with torch.no_grad():
for data, target in test_loader:
non_target_mask = (target != target_label)
if not non_target_mask.any():
continue
data_to_attack = data[non_target_mask]
data_to_attack = data_to_attack.to(device)
data_to_attack[:, 0, -trigger_size:, -trigger_size:] = trigger_value
output = model(data_to_attack)
pred = output.argmax(dim=1, keepdim=True)
successful_attacks += (pred.view(-1) == target_label).sum().item()
total_attack_attempts += len(data_to_attack)
asr = 100. * successful_attacks / total_attack_attempts
print(f'攻击成功率 (ASR) 评估: 攻击成功次数: {successful_attacks}/{total_attack_attempts} ({asr:.2f}%)\n')
return asr
def main():
BATCH_SIZE = 64
EPOCHS = 15
LEARNING_RATE = 0.01
TARGET_LABEL = 0
POISON_RATE = 0.1
TRIGGER_SIZE = 4
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset_clean = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
print("=" * 50)
print("开始训练干净模型 (Clean Model)...")
clean_train_loader = DataLoader(train_dataset_clean, batch_size=BATCH_SIZE, shuffle=True)
clean_model = SimpleCNN().to(device)
optimizer_clean = optim.SGD(clean_model.parameters(), lr=LEARNING_RATE)
for epoch in range(1, EPOCHS + 1):
train(clean_model, device, clean_train_loader, optimizer_clean, epoch)
print("\n--- 评估干净模型 ---")
evaluate(clean_model, device, test_loader)
evaluate_attack_success_rate(clean_model, device, test_loader, TARGET_LABEL, TRIGGER_SIZE)
print("\n" + "=" * 50)
print("开始训练后门模型 (Backdoored Model)...")
train_dataset_for_poisoning = datasets.MNIST('./data', train=True, download=True, transform=transforms.ToTensor())
poisoned_train_dataset_tensor = BadNet(train_dataset_for_poisoning, TARGET_LABEL, POISON_RATE, TRIGGER_SIZE)
poisoned_images = poisoned_train_dataset_tensor.tensors[0]
poisoned_labels = poisoned_train_dataset_tensor.tensors[1]
normalize_transform = transforms.Normalize((0.1307,), (0.3081,))
normalized_poisoned_images = torch.stack([normalize_transform(img) for img in poisoned_images])
final_poisoned_dataset = TensorDataset(normalized_poisoned_images, poisoned_labels)
poisoned_train_loader = DataLoader(final_poisoned_dataset, batch_size=BATCH_SIZE, shuffle=True)
backdoored_model = SimpleCNN().to(device)
optimizer_backdoor = optim.SGD(backdoored_model.parameters(), lr=LEARNING_RATE)
for epoch in range(1, EPOCHS + 1):
train(backdoored_model, device, poisoned_train_loader, optimizer_backdoor, epoch)
print("\n--- 评估后门模型 ---")
print("1. 在干净测试集上的表现 (评估其隐蔽性):")
evaluate(backdoored_model, device, test_loader)
print("2. 攻击成功率 (评估其攻击性):")
evaluate_attack_success_rate(backdoored_model, device, test_loader, TARGET_LABEL, TRIGGER_SIZE)
print("\n" + "=" * 50)
print("可视化一些样本...")
poisoned_indices = [i for i, label in enumerate(poisoned_labels) if label == TARGET_LABEL]
original_labels = train_dataset_for_poisoning.targets
sample_idx = -1
for idx in poisoned_indices:
if original_labels[idx] != TARGET_LABEL:
sample_idx = idx
break
poisoned_sample_img = poisoned_images[sample_idx].squeeze().numpy()
original_label = original_labels[sample_idx].item()
test_iter = iter(test_loader)
test_imgs, test_labels = next(test_iter)
attack_test_idx = (test_labels != TARGET_LABEL).nonzero()[0].item()
attack_test_img = test_imgs[attack_test_idx].clone()
attack_test_label = test_labels[attack_test_idx].item()
attack_test_img_triggered = attack_test_img.clone()
attack_test_img_triggered[0, -TRIGGER_SIZE:, -TRIGGER_SIZE:] = (1.0 - 0.1307) / 0.3081
clean_pred_on_triggered = clean_model(attack_test_img_triggered.unsqueeze(0).to(device)).argmax().item()
backdoor_pred_on_triggered = backdoored_model(attack_test_img_triggered.unsqueeze(0).to(device)).argmax().item()
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
axs[0].imshow(poisoned_sample_img, cmap='gray')
axs[0].set_title(f"训练集中的一个投毒样本\n原始标签: {original_label}, 投毒后标签: {TARGET_LABEL}")
axs[0].axis('off')
axs[1].imshow(attack_test_img.squeeze().numpy(), cmap='gray')
axs[1].set_title(f"一个干净的测试样本\n真实标签: {attack_test_label}")
axs[1].axis('off')
axs[2].imshow(attack_test_img_triggered.squeeze().numpy(), cmap='gray')
axs[2].set_title(
f"添加触发器后的测试样本\n干净模型预测: {clean_pred_on_triggered}\n后门模型预测: {backdoor_pred_on_triggered} (攻击成功!)")
axs[2].axis('off')
plt.tight_layout()
plt.show()
if __name__ == '__main__':
main()
|