
Pythorch_Tutorial_Basic
机器学习的四块分别是: 1.DataSet 2.Model 3.Training 4.Inferring #
线性回归模型 ## DataSet:
首先我们先假设一个很简单的数据集: 1
2
3
4
5
6X Y
--------------
1 2
2 4
3 6
4 ?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
print("w=", f"{w : .2f}")
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print("\t", f"{x_val:.2f}", f"{y_val:.2f}", f"{y_pred_val:.2f}", f"{loss_val:.2f}")
print("MSE=", f"{l_sum / 3 : .2f}")
w_list.append(w)
mse_list.append(l_sum / 3)
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
epoch_list = []
cost_list = []
print("Predict (before training) ", 4, forward(4))
for epoch in range(1000):
epoch_list.append(epoch)
cost_val = cost(x_data, y_data)
cost_list.append(cost_val)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print("\tEpoch :", f"{epoch : .2f}", "w =", f"{w : .2f}", "cost =", f"{cost_val : .2f}")
print("Predict (after training) ", 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.xlabel("Epoch")
plt.ylabel("Cost")
plt.show()
更新代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
for x, y in zip(xs, ys):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(xs, ys):
for x, y in zip(xs, ys):
return 2 * x * (x * w - y)
epoch_list = []
loss_list = []
print("Predict (before training) ", 4, forward(4))
for epoch in range(1000):
epoch_list.append(epoch)
loss_val = cost(x_data, y_data)
loss_list.append(loss_val)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print("\tEpoch :", f"{epoch : .2f}", "w =", f"{w : .2f}", "loss =", f"{loss_val : .2f}")
print("Predict (after training) ", 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.xlabel("Epoch")
plt.ylabel("Cost")
plt.show()
梯度下降:运算性能高,但是效果不如随机下降 随机梯度下降:效果性能高,但是运算速率低 所以我们用MiNiBatch(小批量的)进行处理 这样之后,优化器的问题暂时先这样处理(局部最优问题怎么解决??) # 反向传播 解释起来很麻烦,所以我选择用图片
这个是正向过程
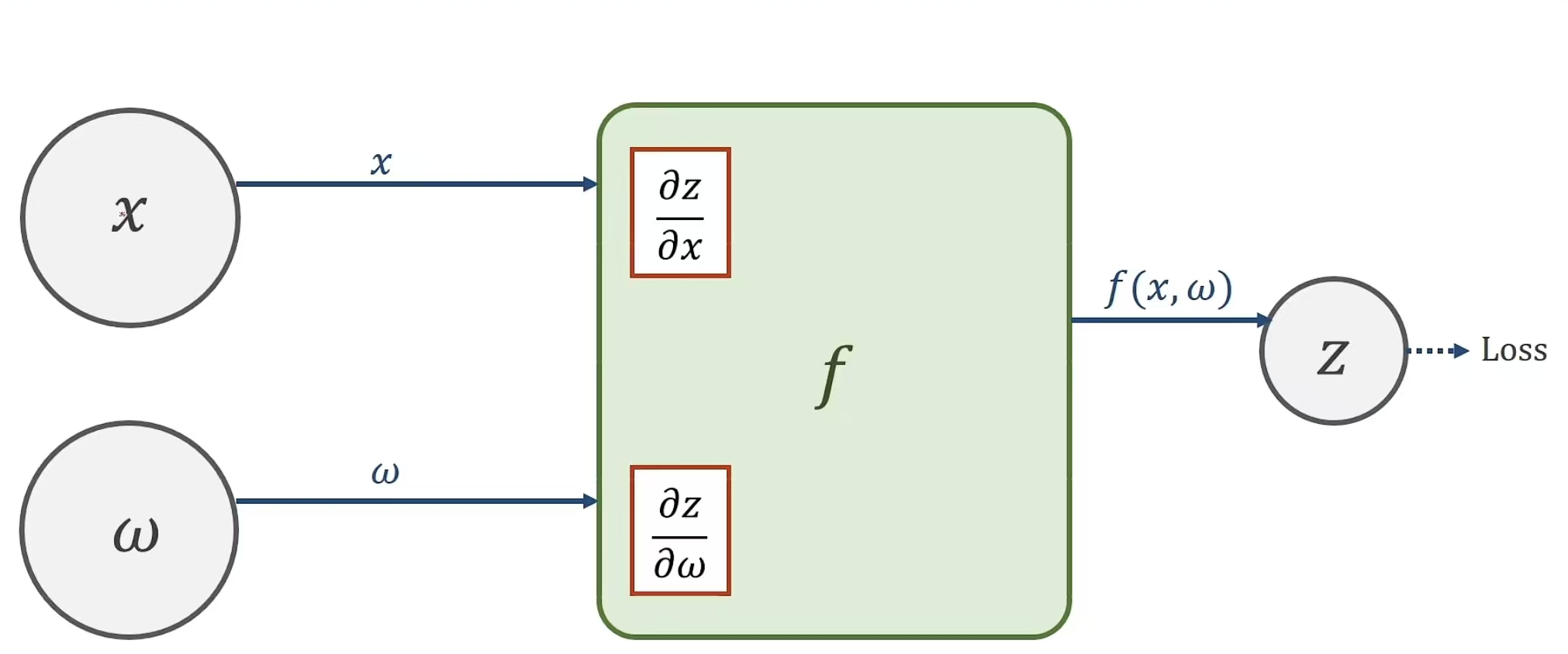
进行反馈来计算相应的偏导
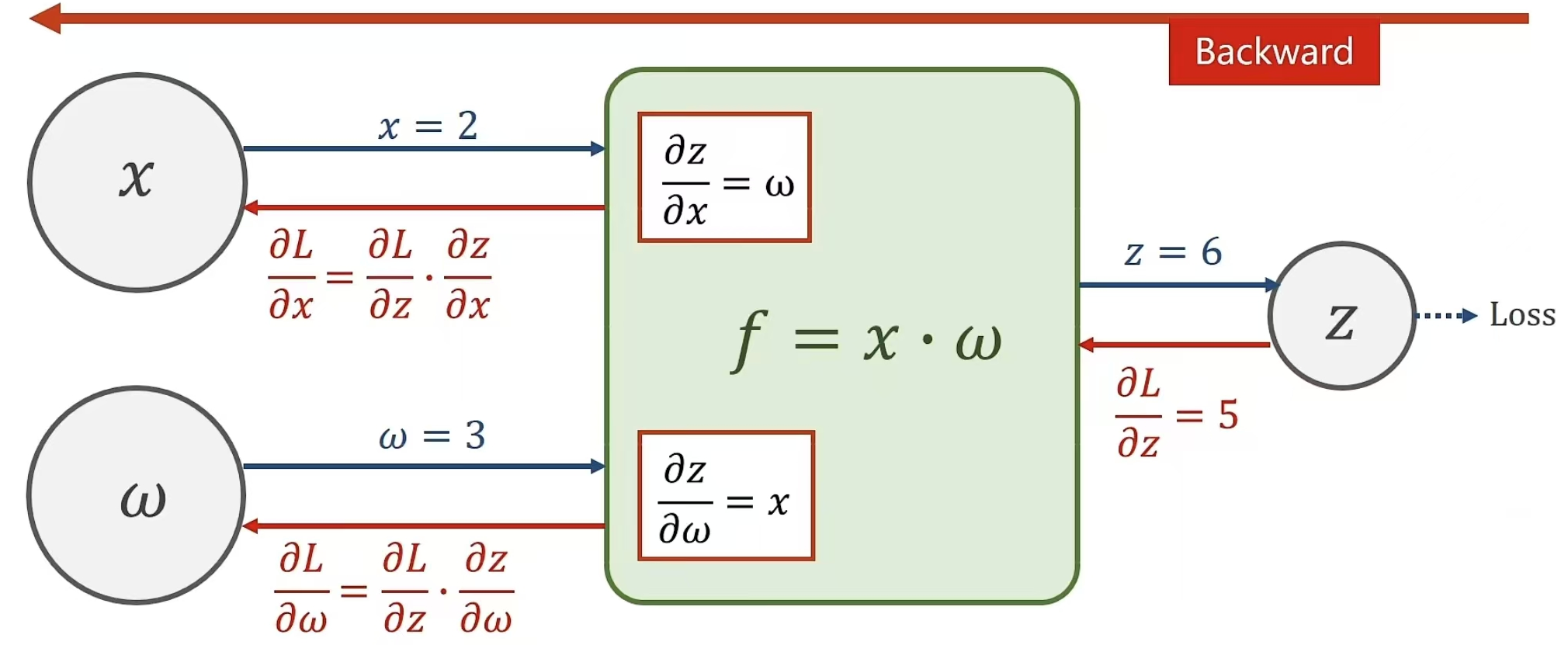
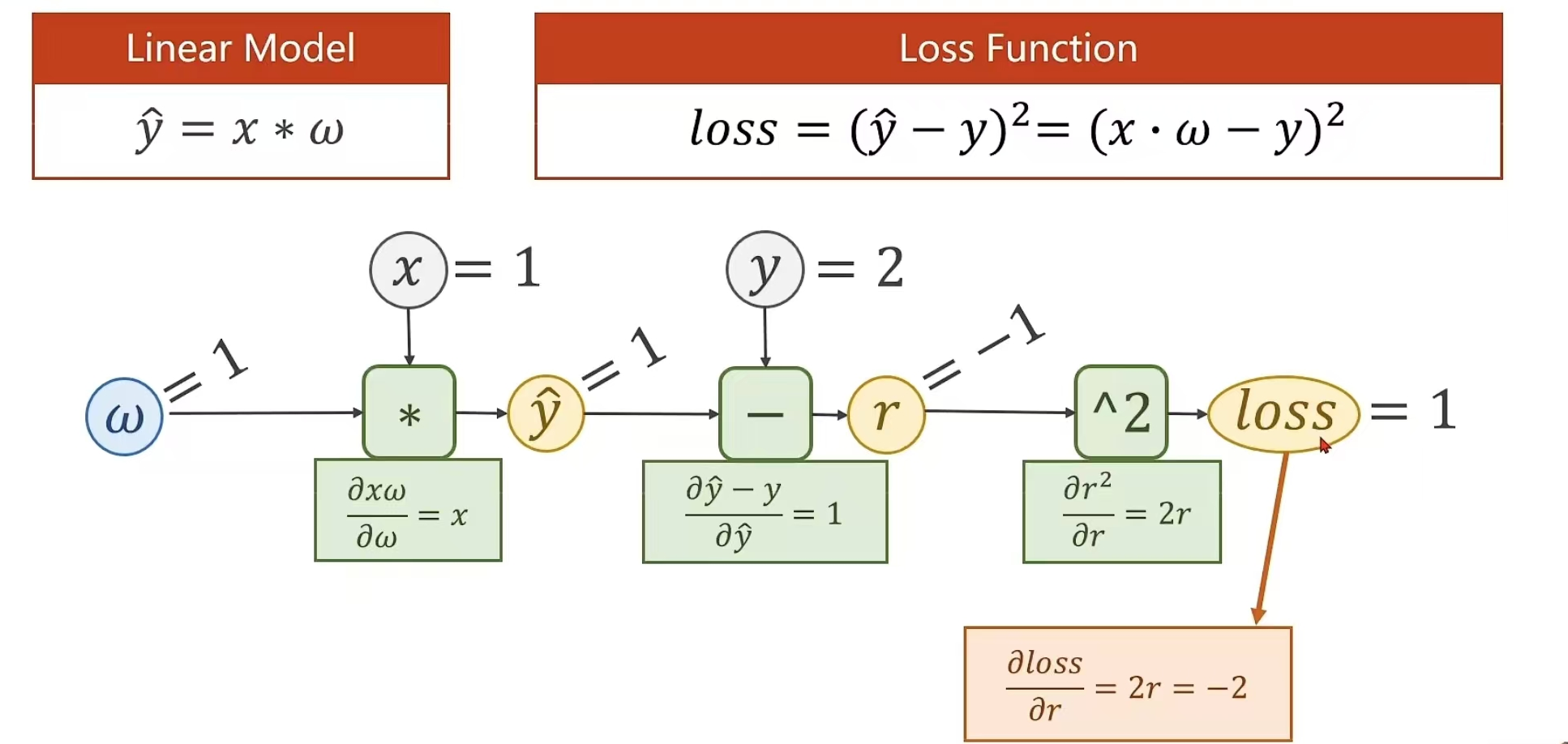
例题:
这个虽然麻烦,但是实现起来很简单,只需一行代码,对上一节代码稍作修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict (before training) ", 4, forward(4).item())
l = 0
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print("\tgrad:", x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print("process: ", epoch, l.item())
print("predict (after training)", 4, forward(4).item())
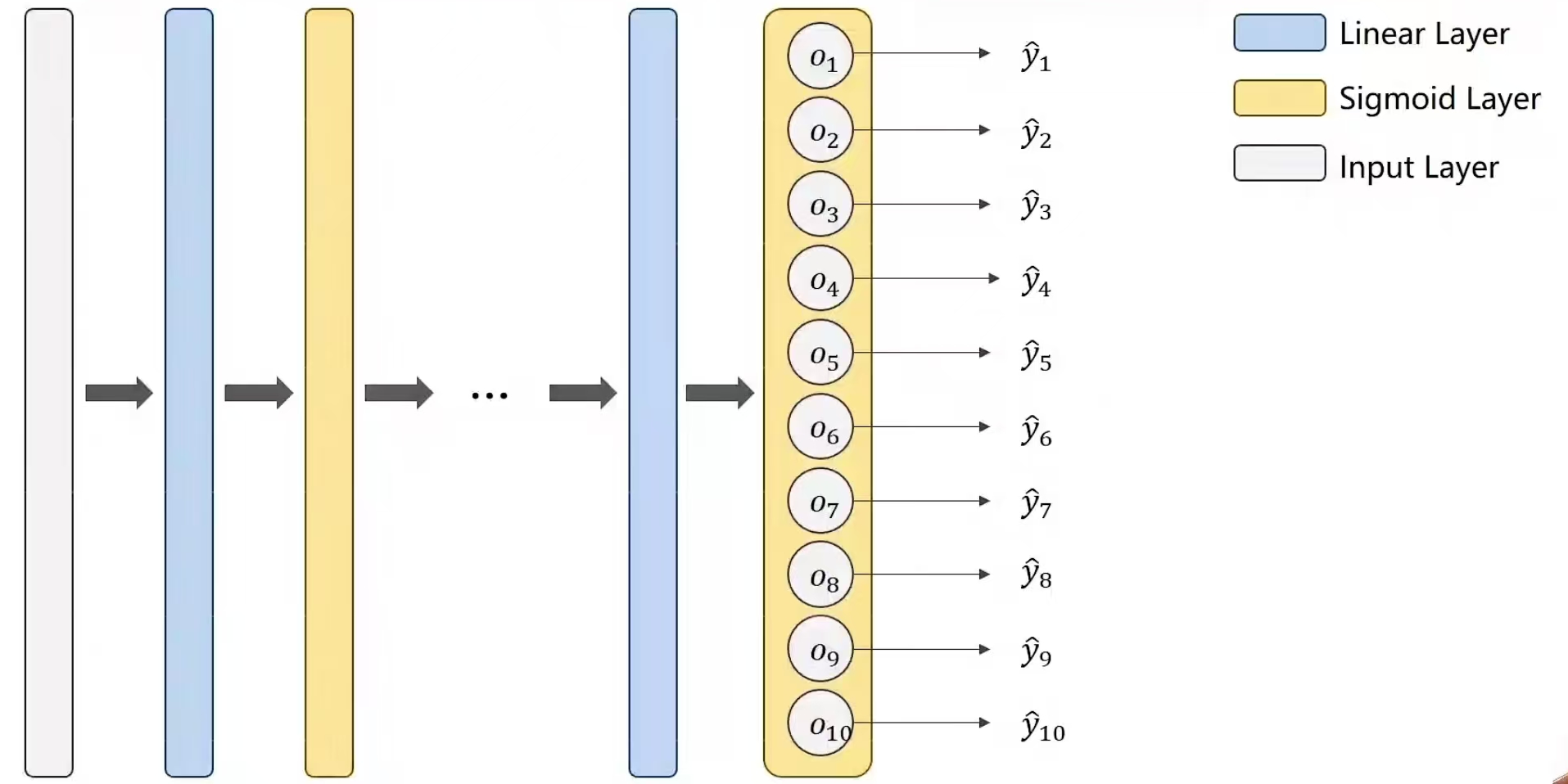
所以,我们可以另外用一个函数Softmax,解决这个问题,令通过这个函数之后,输出可以满足我们的要求
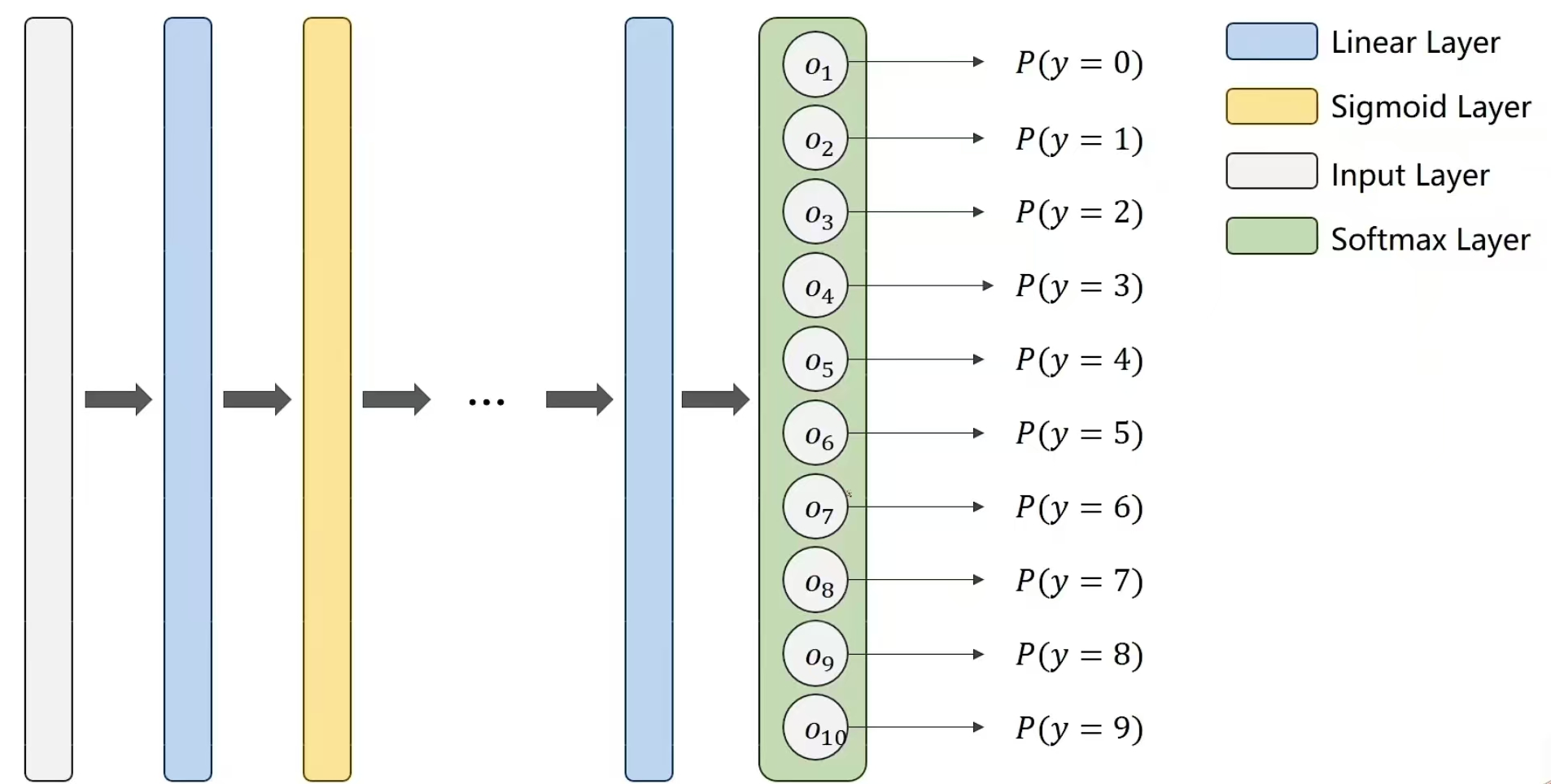
如何实现呢?
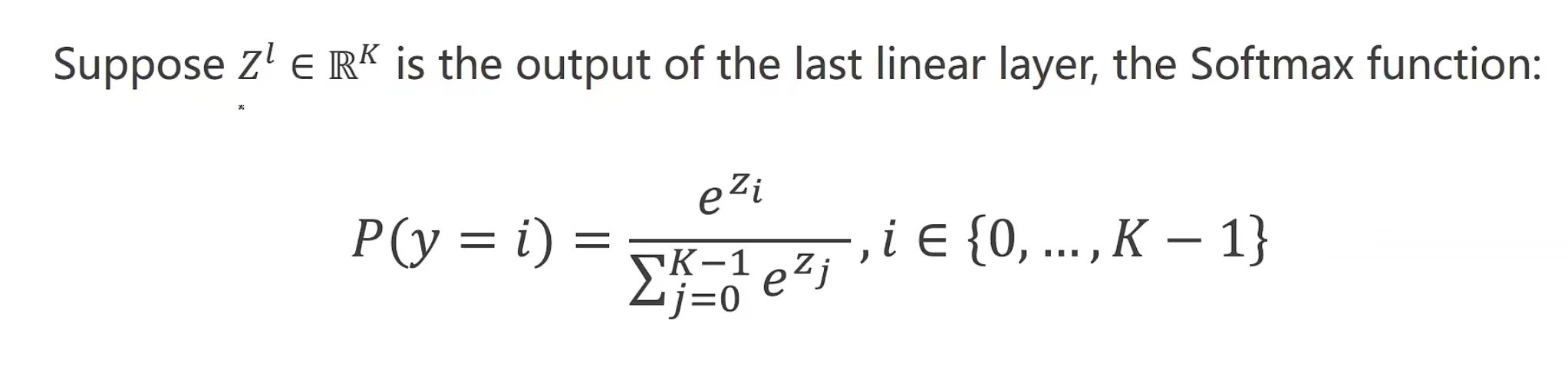
损失计算,使用交叉熵。 pythorch提供了Softmax以及log_softmax两个计算函数 自然,也有两个损失函数,NLLLoss,以及CrossEntropyLoss
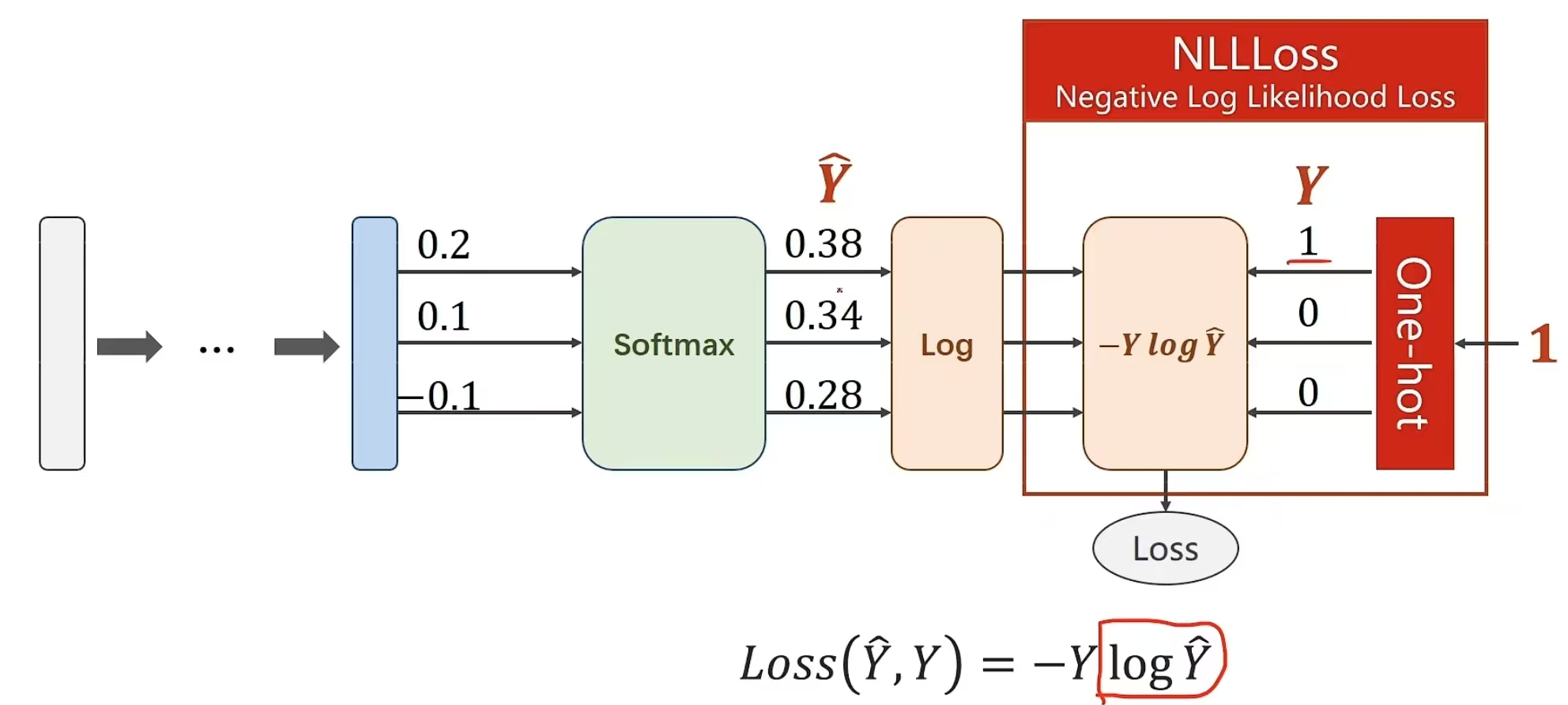
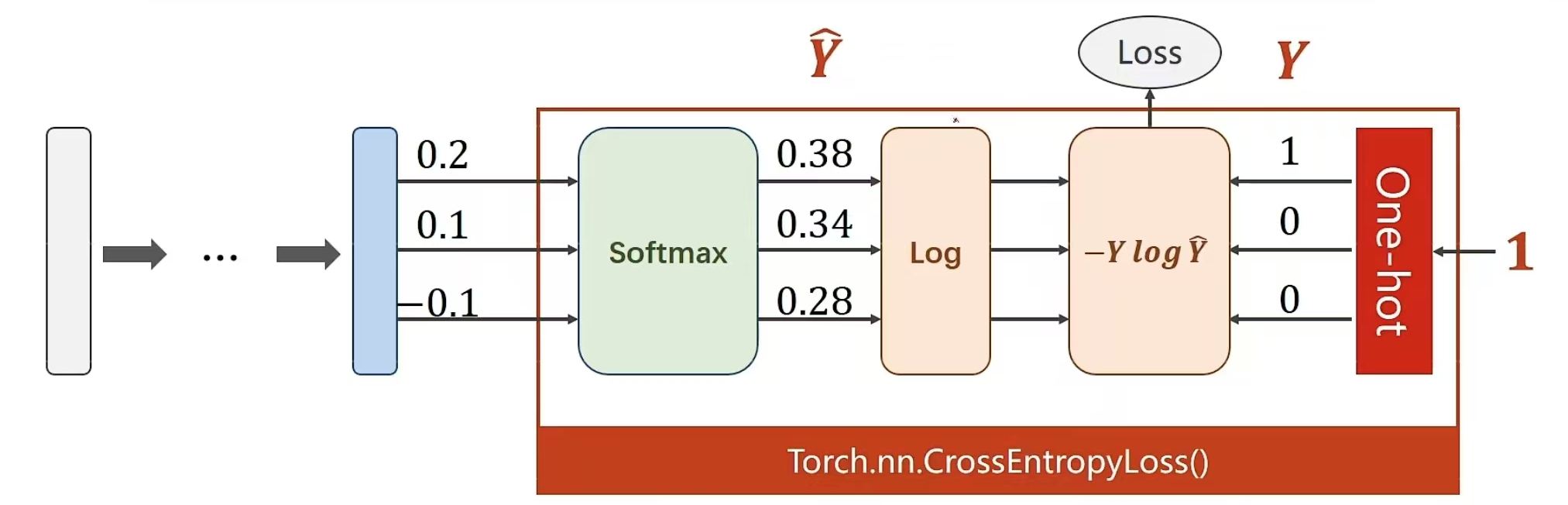
交叉熵损失与NLLLoss损失的差别:
等我搞清楚再写~
下面就是利用多分类知识,对MNIST进行代码实现: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112# mnist多分类问题
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# 1.准备数据集
# batch大小
batch_size = 64
transform = transforms.Compose(
[
# python用pillow读取图像,神经网络处理时,希望处理的数据是正态分布,
# 1.转换成图像张量,原图像维度由28*28变成1*28*28,(单通道变成多通道)(把W*H*C-->C*W*H)
# 原图像像素值由0~255转换成0~1
transforms.ToTensor(),
# 2.线性变换变成标准正态分布
transforms.Normalize((0.1307,), (0.3081,))
]
)
train_dataset = datasets.MNIST('../data', train=True, download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST('../data', train=False,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=True,
batch_size=batch_size)
# 2.设计模型
class Net(torch.nn.Module):
#
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 输入是N个样本,1维的28*28图像(是一个4阶张量)
# 全连接神经网络,要求输入是一个矩阵,所以我们需要将1*28*28(3阶张量变成1维向量)
# -1行(知道计算N),784列(28*28)
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 最后一步不需要激活函数
return self.l5(x)
model = Net()
# 损失与优化器
criterion = torch.nn.CrossEntropyLoss()
# 优化器:多了一个momentum=0.5,冲量
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 4.训练与测试
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
# 优化器清零
optimizer.zero_grad()
# forward + backword + updata
output = model(inputs)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
def test():
correct = 0
total = 0
# 不需要计算梯度
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# _ 表示我们不关心的那个返回值。
# 这个返回两个值:每个样本在第 dim=1 维度上的最大值,即每一行的最大值(我们在这里不需要这个值,所以用 _ 忽略掉)。
# 每个样本对应的最大值的索引,即 predicted,表示模型预测的类别标签。
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy on test set: %d %%" % (100 * correct / total))
def main():
for epoch in range(10):
train(epoch)
test()
if __name__ == '__main__':
main()
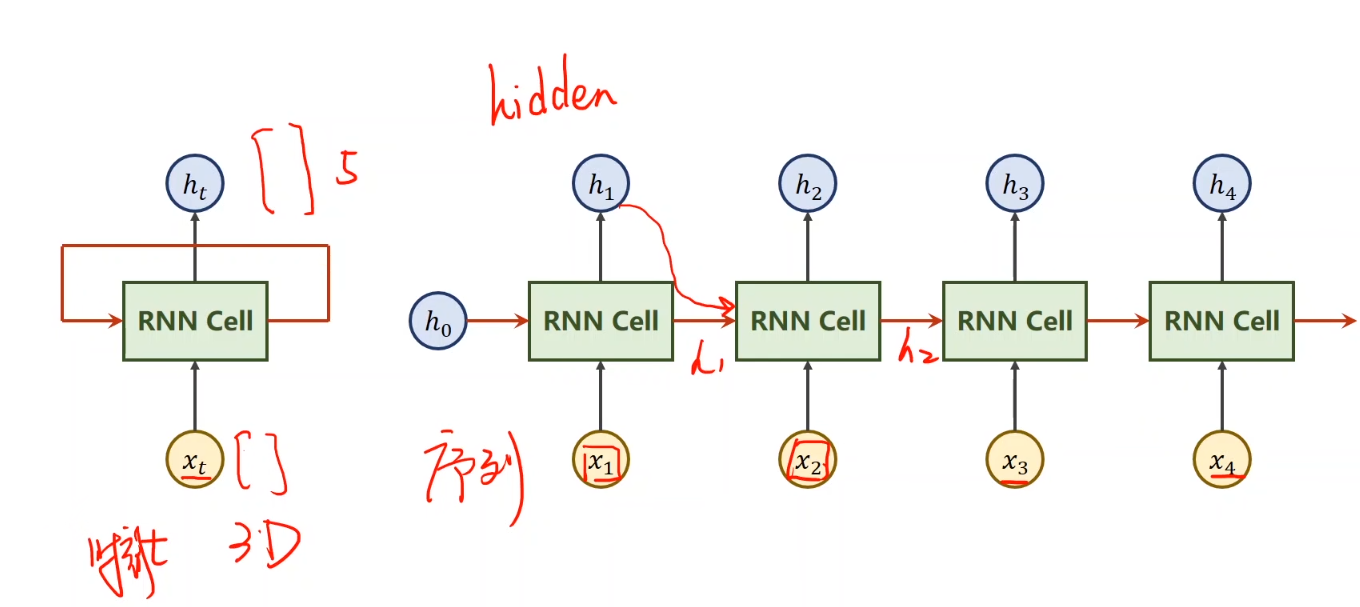
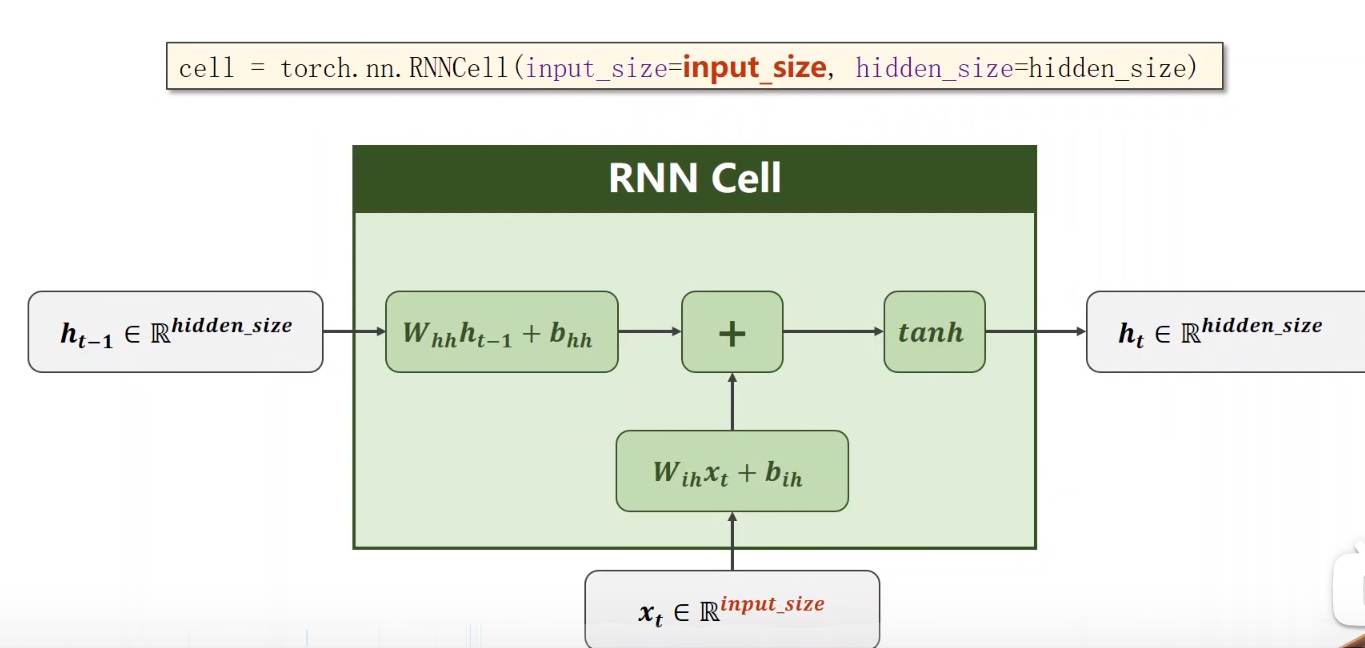
,那么,循环神经网络,就是多个RNNcell进行操作嘛,也不是很难理解~ 下面,还有一个num_layer的概念,很嗨理解,看图即可:
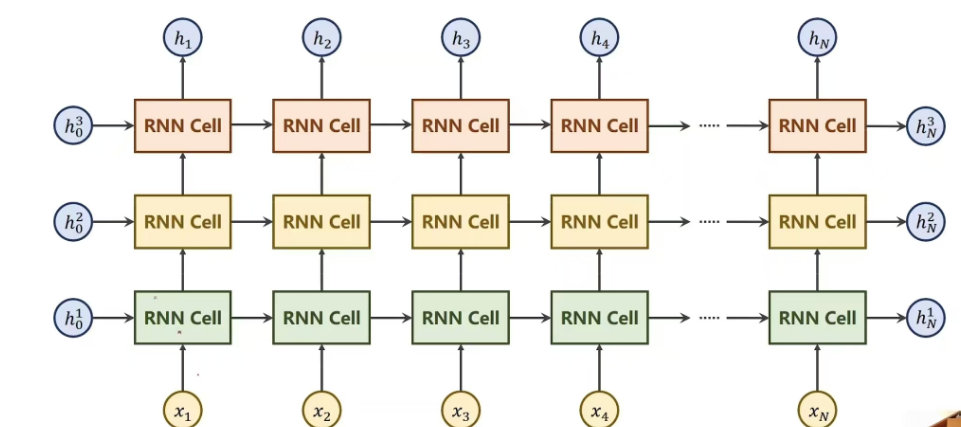
其实就是多层嵌套
下面,举一个pythorch中使用rnn的小李子:(主要是对维度的理解),(其实,我也没理解太明白。。。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import torch
batch_size = 2
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print("Output size: ", out.shape)
print("Output: ", out)
print("Hidden size: ", hidden.shape)
print("Hidden: ", hidden)
好,我们对序列到序列进行一个例子,来看一下RNN模型的训练(分成RNNcell以及RNN) 下面,举一个例子:hello –> olleh(其实就是一个逆序) (对了,还有一个小知识点,one-hot矩阵 我们看一张图就可理解,很简单
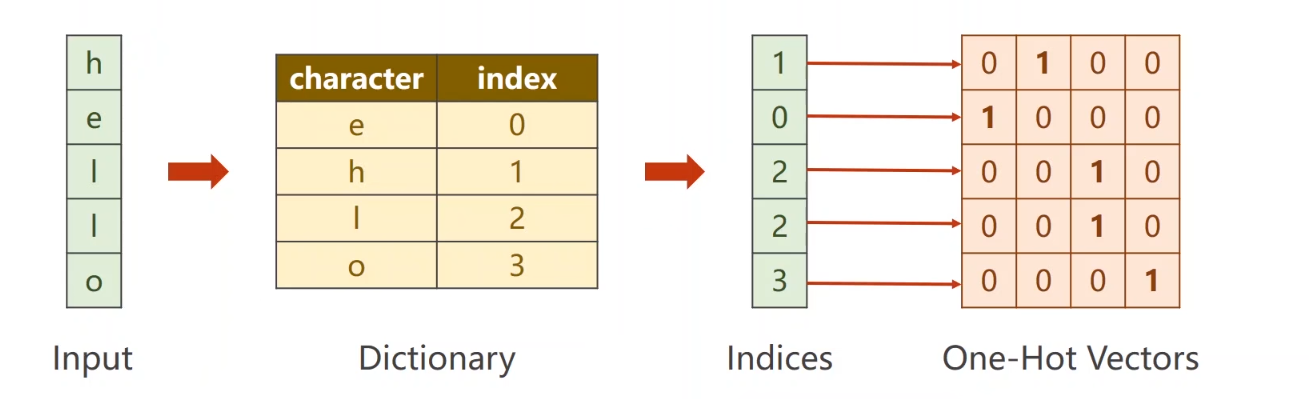
这是onehot矩阵 数据量较大时可以考虑embedding或者word2vec,举完这个例子之后,我会说一下embedding
RNNcell 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 2, 2, 0, 1]
# 独热向量
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print("Predicted string: ", end='')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss = %.4f' % (epoch+1, loss.item()))
# 测试集,不过没啥用,这个数据太小了,根本没有训练那效果
# net.eval()
#
# test_data = [3, 1, 0, 0, 2]
# test_one_hot = [one_hot_lookup[x] for x in test_data]
# test_inputs = torch.Tensor(test_one_hot).view(-1, batch_size, input_size)
#
# hidden = net.init_hidden()
#
# print("Test Prediction: ", end='')
# for input in test_inputs:
# hidden = net(input, hidden)
# _, idx = hidden.max(dim=1)
# print(idx2char[idx.item()], end='')
#
# print()
RNN (变化不多,约等于0) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57import torch
input_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 2, 2, 0, 1]
# 独热向量
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(5, batch_size, input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,
hidden_size=hidden_size,
num_layers=num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join(idx2char[x] for x in idx), end='')
print(', Epoch [%d/15] loss = %.4f' % (epoch+1, loss.item()))
ok,简单了解了RNN的使用。 ### embedding(额外理解) 简单了解one-hot之后,你就应该知道,数据量过大的时候,这个东西不太好用 第一:维度太大 第二:数据松散 第三:这是个硬编码 那好,我们应该怎么,找一个低维、稠密、并可以从数据学习的东西呢 现在比较流行的就是embedding
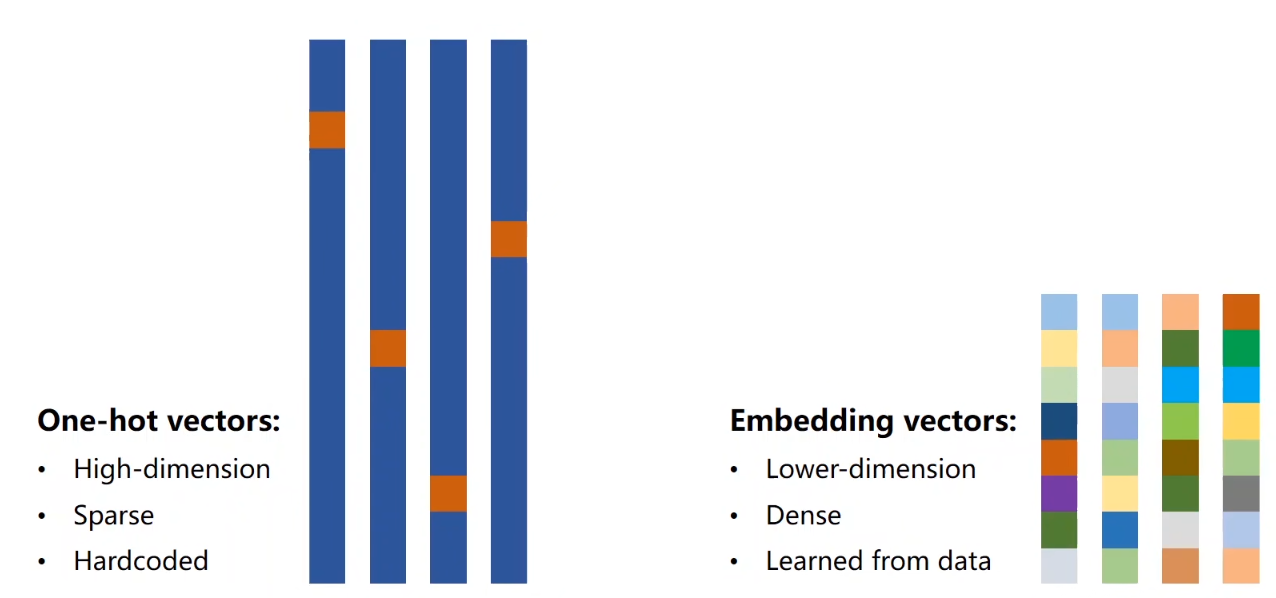
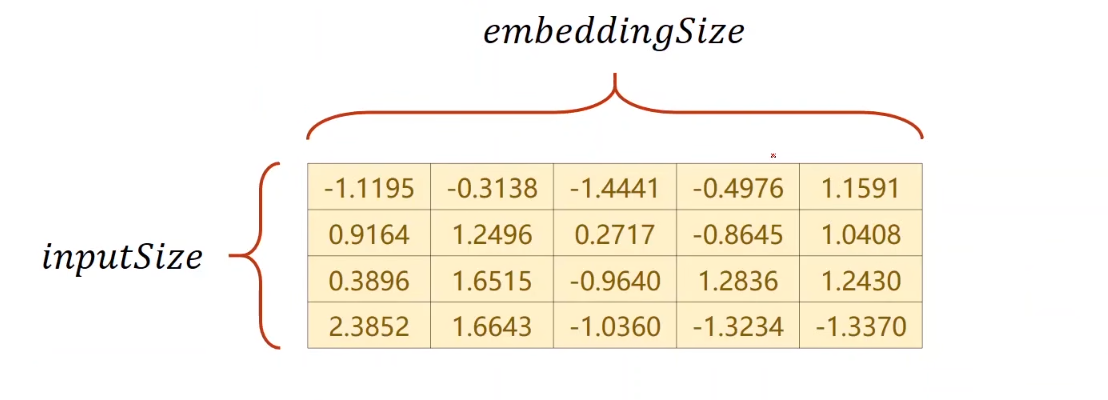
可以进行一个数据降维 例如,我们的输入是4维,然后我们利用嵌入层,(维度是我们自己定义的),假如说是5维,我们构建一个类似下图的4x5的矩阵,就可以将4维变成5维(也?好像做了一个升维的操作hhhhh,不过无所谓)
下面呢,我们的网络就是将输入通过嵌入层变成一个稠密的表示,在经过RNN,并且由于隐层的维度应该和我的分类的数量一致,为了避免embedding造成不一致,我们在接一个线性层
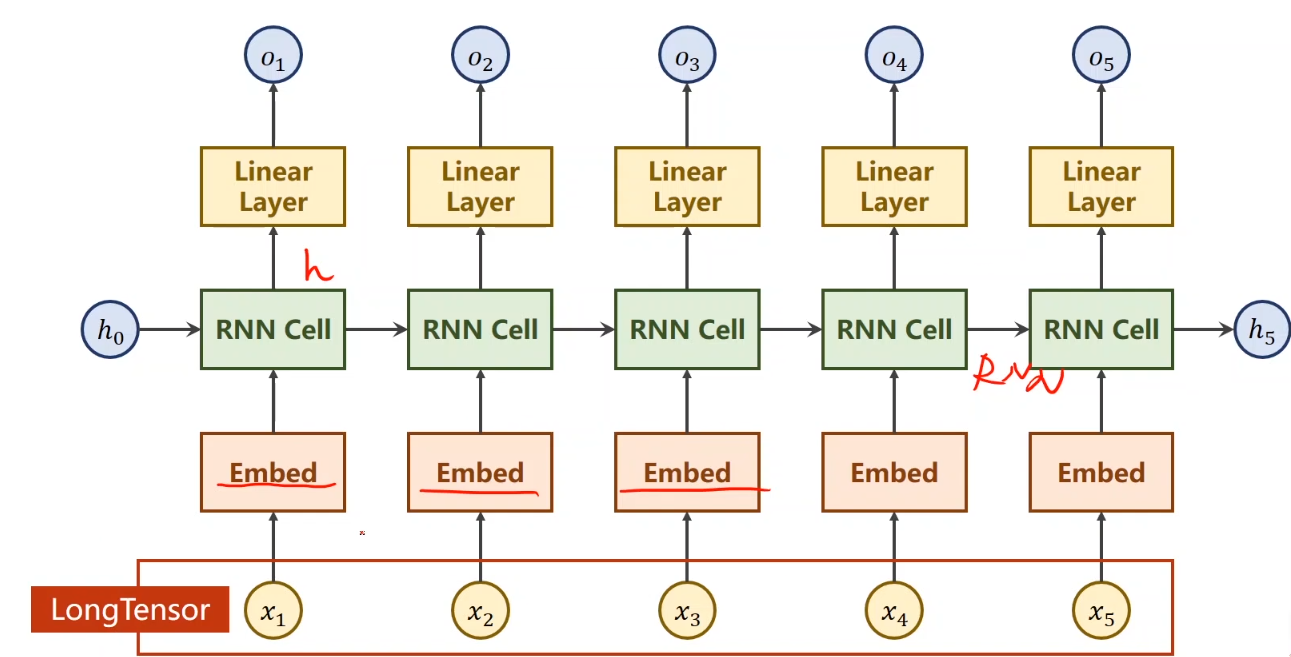
差不多长这个样
(还有一些函数的参数传入说明,我没太搞明白,就不写了,感兴趣的可以自己查查)
1 | import torch |
跑一下可以知道,这三个代码,loss一个比一个低
下一节,来看一个具体的RNN使用例子· # 循环神经网络(Adance RNN)
一个具体的分类例子,对一个名字然后预测其国家的模型
先放一下代码,看了几个小时,有点麻 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234import csv
import gzip
import math
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset, DataLoader
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCH = 100
N_CHARS = 128
USE_GPU = True
# 时间计时模块
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
# 数据集类
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
# 数据集还是测试集的选择
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
# 数据集读取,看打包类型选取不同的包进行读取
# 此出选用gzip以及csv进行读取,还有pickle、HDFS、HD5等等
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) # 读取行,每一行都是(name, language/country)
# 提取name
self.name = [row[0] for row in rows]
self.len = len(self.name)
# 提取国家
self.country = [row[1] for row in rows]
# 从得到的国家里面,去重之后得到一个字典,与索引一一对应,并得到国家总数
self.country_list = list(sorted(set(self.country)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def __getitem__(self, index):
# 返回对应名字,以及名字对应国家的对应序号(dict里面的value)
return self.name[index], self.country_dict[self.country[index]]
def __len__(self):
return self.len
# 通过country_list得到字典
def getCountryDict(self):
country_dict = dict()
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
# 返回索引对于的国家
def idx2country(self, index):
return self.country_list[index]
# 返回国家数量
def getCountryNum(self):
return self.country_num
# 数据集的准备
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = trainset.getCountryNum()
class RNNClassifier(torch.nn.Module):
# bidirectional双向循环神经网络
def __init__(self, input_size, hidden_size, output_size, n_layer, bidirectional=True):
super(RNNClassifier, self).__init__()
self.n_layer = n_layer
self.hidden_size = hidden_size
self.n_direction = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layer, bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_direction, output_size)
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layer * self.n_direction,
batch_size, self.hidden_size)
return create_tensor(hidden)
def forward(self, x, seq_lengths):
# 转置,变成embedding层需要的维度,从batch * seqLen -> seqLen * batch
x = x.t()
batch_size = x.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(x) # 变成3维了
# puck up ,提高效率
seq_lengths = seq_lengths.cpu().to(torch.int64)
gru_input = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(gru_input, hidden)
if self.n_direction == 2:
hidden_cat = torch.cat([hidden[-2], hidden[-1]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr)
def make_tensors(names, countries):
# 名字变成acsii列表,返回一个元组
sequences_and_lengths = [name2list(name) for name in names]
# 取出列表以及长度
name_sequences = [s1[0] for s1 in sequences_and_lengths]
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries = countries.long()
# padding操作
seq_tenser = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tenser[idx, :seq_len] = torch.LongTensor(seq)
# 排序
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tenser = seq_tenser[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tenser), \
create_tensor(seq_lengths), \
create_tensor(countries)
def train_model():
"""
loss初始为0在循环之外;
将训练集传入,取出数据,生成输入数据,长度,标签
放入classifier模型训练
利用criterion函数计算损失值
梯度归零
反向传播
优化器迭代,更新参数(权重,偏置)
损失值累加
输出
:return:所有数据一次的损失
"""
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}', end='')
print(f'[{i * len(inputs)} / {len(trainset)}]', end='')
print(f'loss = {total_loss / (i * len(inputs))}')
return total_loss
def test_model():
"""
测试集
不用计算梯度
取出数据
将特征放入,计算预测值
求预测数据中的最大值,dim=1--每一行
损失累加
输出
:return:错误率
"""
correct = 0
total = len(testset)
print("evaluating trained model ...")
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct} / {total} {percent} %')
return correct / total
# 主循环
if __name__ == '__main__':
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device)
# 损失函数以及优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
start = time.time()
print("Training for %d epoch..." % N_EPOCH)
acc_list = []
for epoch in range(1, N_EPOCH + 1):
train_model()
acc = test_model()
acc_list.append(acc)
print(f"Device: {torch.cuda.current_device()} - {torch.cuda.get_device_name(torch.cuda.current_device())}")
epoch = np.arange(1, len(acc_list) + 1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()








