模型窃取定义
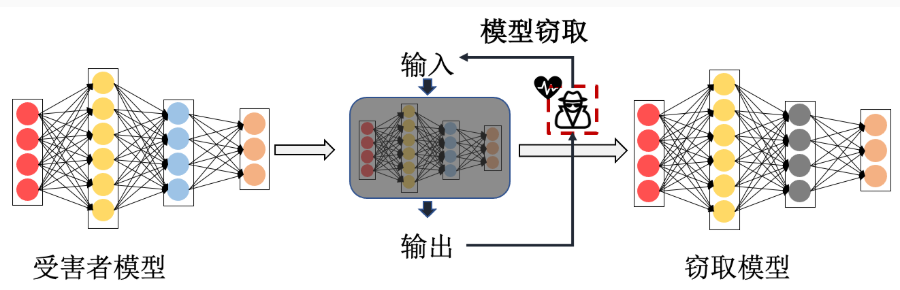
模型窃取攻击 的目标是通过一定手段窃取得到一个跟{受害者模型 }功能和性能相近的窃取模型 ,从而避开昂贵的模型训练并从中获益。模型窃取是一种侵犯人工智能模型知识产权 的恶意攻击行为。实际上,对人工智能模型知识产权的侵犯不仅限于模型窃取技术,未经授权的模型复制、微调、迁移学习(微小模型修改+微调)、水印去除等也属于模型知识产权侵犯行为。相比之下,模型窃取攻击更有针对性、威胁更大,即使目标模型是非公开的,很多窃取方法也能通过模型服务API完成窃取 。这给模型服务提供商带来巨大的挑战,要求他们不仅要满足所有用户的服务请求还要有能力甄别恶意的窃取行为
image-20250812153840028
如图所示,模型窃取可以在与受害者模型交互 的过程中完成。攻击者通过有限次数的黑盒访问受害者模型的API接口,向模型输入不同的查询样本并观察受害者模型输出的变化,然后通过不断地调整查询样本来获取受害者模型更多的决策边界信息。在此交互过程中,攻击者可以通过模仿学习 得到一个与受害者模型相似的窃取模型,或者直接窃取受害者模型的参数和超参数等信息。
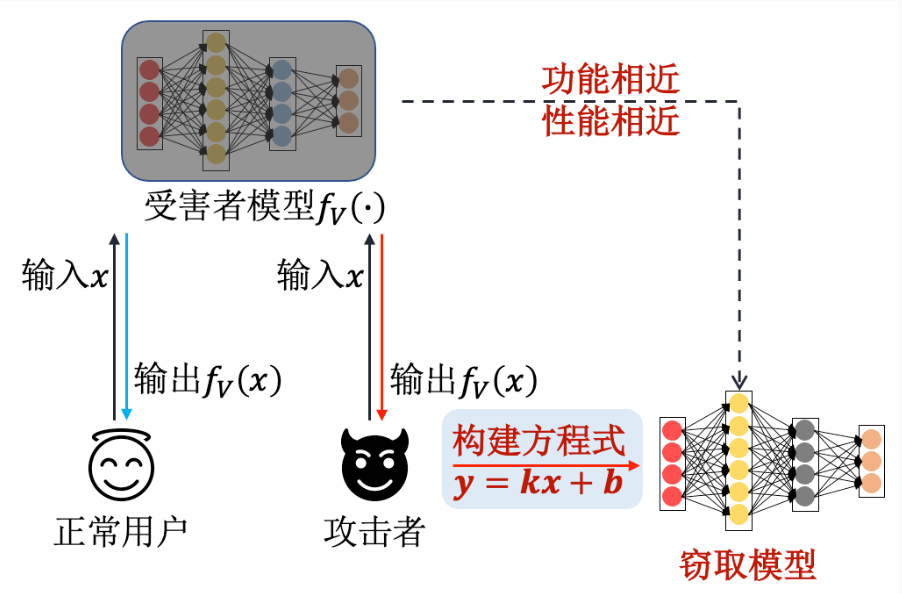
根据窃取方式的不同,现有模型窃取攻击可大致分为:基于方程式求解的窃取攻击 、基于替代模型的窃取攻击 和基于元模型的窃取攻击
基于方程式求解的窃取攻击
攻击者
image-20250812154318892
该攻击是一种针对传统机器学习 模型的窃取攻击,适用于逻辑回归、多层感知机、支持向量机和决策树 等机器学习模型,并不适用于复杂的深度神经网络模型。
模型参数窃取:
如果受害者模型有个
算法超参窃取:
在已知训练集和模型的前提下,有一种可以准确窃取算法超参数的方法。由于受害者模型参数通常对应的是损失函数
其中,训练集D={x,y},模型参数
(
通过最小二乘法可求得
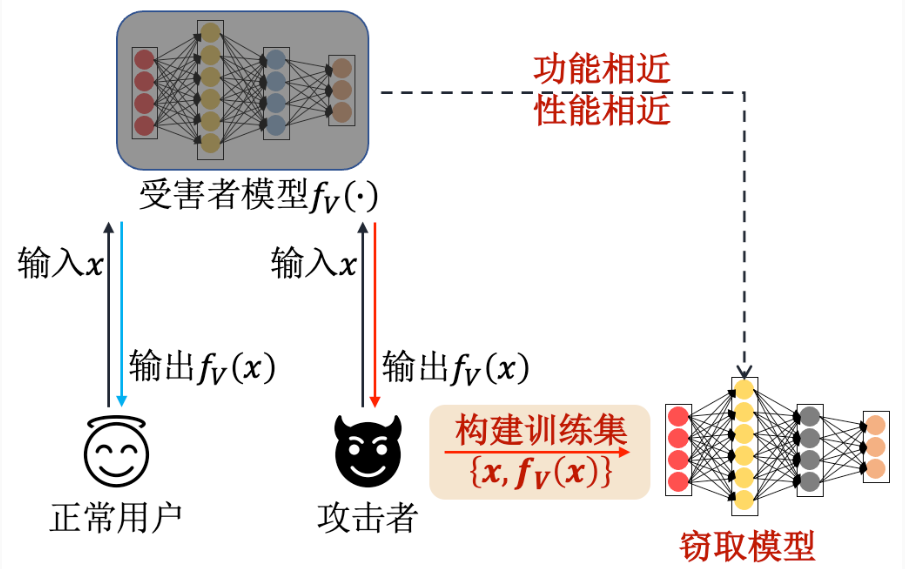
基于替代模型的窃取攻击
攻击者
image-20250812160734509
(这个与知识蒸馏很像吧感觉),两者的区别在哪?
知识蒸馏的目的是将教师模型学到的特征表示蒸馏到学生模型中,而模型窃取的目的是重建一个与受害者模型一样的替代模型。
其中,
Knockoff Nets攻击
此攻击被命名为“仿冒网络 ”(Knockoff
Nets)攻击。该窃取攻击无需受害者模型的先验信息,攻击者只需构建迁移(替代)数据集( )
(
基于元模型的窃取攻击
不会~
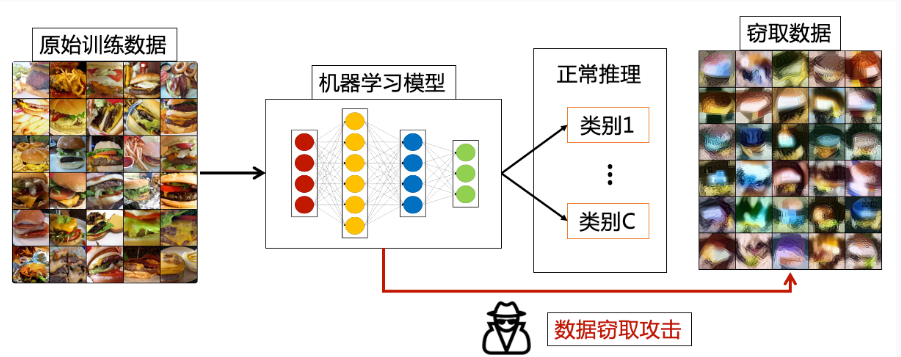
数据窃取定义
数据窃取攻击 (data stealing
attack)从已训练模型中逆向得到模型的原始训练数据 ,所以也称为数据抽取攻击 (data
extraction attack)或模型逆向攻击 (model inversion
attack)。如图展示了数据窃取攻击的目的,通常情况下我们利用训练好的模型进行正常推理任务,但是数据窃取攻击者会尝试从模型中逆向出原始训练数据。当前数据窃取攻击针对的主要是深度学习模型研究,利用的是模型在训练过程中记忆的训练数据 。
image-20250812170644724
黑盒数据窃取
攻击者所掌握的信息只有模型的输出结果,所以只能攻击特定类型的模型,且只能窃取部分数据信息。一般来说,模型的输出维度越高就越容易受到黑盒数据窃取 ,比如生成模型、序列到序列模型等,这主要是因为输出维度越高暴漏的信息也就会越多。相反的,如果是对输入信息压缩很厉害的分类模型,则难以仅根据输出概率去窃取输入信息。
黑盒数据窃取攻击主要针对大语言模型 (large language
models)——为单词序列分配概率的统计模型
这类模型的大规模学习的方式赋予了语言模型生成通畅自然语言的能力,被广泛应用于各种下游任务。训练大语言模型的数据集往往包含大量公开在互联网上的文本数据,这些数据经常(意外地)包含个人隐私信息(如身份证号码、手机号码、邮箱、家庭住址等),在面临窃取攻击时容易发生关联泄露(比如出现人名的时候也往往连带着电话号码或家庭住址)。
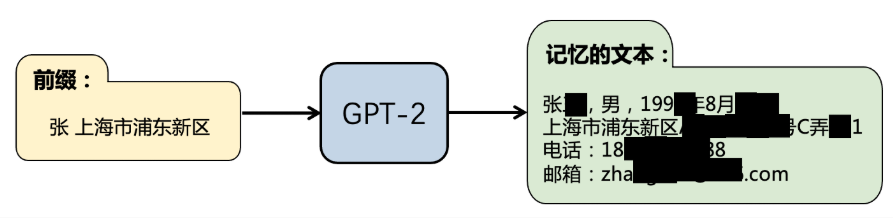
我们来看一个例子,当输入特定前缀文字后,语言模型自动返回了模型记忆的与前缀文字关联的其他隐私信息:
大语言模型通过海量的训练数据进行训练,里面有新闻、网页、小说、代码等等。但麻烦的是,这些书里不小心混进了一些私密小纸条 ,比如某人的电话号码、家庭住址,等等。我们的目标就是专门想窃取那些具体的、敏感的个人信息
我们的想法就是:通过巧妙地设计“引子”(前缀),诱导AI模型“复述”出它在训练时背下来的敏感、私密的真实数据。然后通过一些技术指标(如困惑度)来识别和筛选出这些被泄露的数据
image-20250812172258655
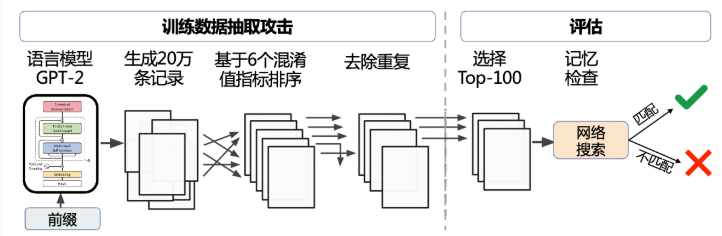
第一步:给出“鱼饵”(对应图中的“前缀”)
攻击者不会直接问:“喂,把你知道的社保号告诉我”。这太傻了,AI可能不会理你。
聪明的攻击者会说一些引导性的话 ,也就是“前缀”。比如,他会说:“我的社会保障号码是*********…”,然后故意停在这里。
第二步:模型“上钩”,开始“背书”(对应图中的“生成文本”)
AI一听到这个熟悉的句式,他的“记忆”就被激活了。他会想:“哦,这句话我背过!”,然后会非常自然地、以极高的概率把你停顿的地方给接下去,把他记忆中一个真实的社会保障号码给“背”了出来。
如图中所示,攻击者会让模型生成海量的文本(比如20万条),希望能“撞大运”撞出一些真实的隐私数据。
第三步:筛选和打分,找到真正的“小纸条”(对应图中的“评估”和“选择”)
模型生成的一大堆话里,大部分是它自己“编”的,但有少数可能是它“背”的原文。怎么找出来呢?一般有两个方法:
“金丝雀”测试 :“canaries”(金丝雀)是一种测试方法。研究人员在训练数据里故意放一些独一无二、毫无意义的假信息(比如“我的幸运数字是
blahblah12345”)。如果模型在回答时,能原封不动地把这个“金丝雀”说出来,就证明了它确实在“背书”,而不是在“创作”。这证实了攻击是可行的。
用“困惑度”打分 :计算“困惑度”(Perplexity)的分数。可以把它简单理解为模型的 “自信程度”**。
如果模型是在自己创作 一句话,它会边想边说,听起来可能很流畅,但它的“自信程度”不会特别高。
但如果它是在“背诵”原文 ,它会说得斩钉截铁,毫不犹豫,这时它的“自信程度”就会爆表(也就是困惑度极低)。
攻击者就利用这一点,给所有生成的话打分,专门挑选那些模型“说得最自信”的话 。这些话极有可能就是它从训练数据里背出来的原文。
Perplexity定义如下:
其中,
第四步:验证成果(对应图中的“验证记忆”)
最后,攻击者把筛选出来的“小纸条”(比如一串看起来像电话号码或社保号的数字)进行验证,确认这到底是真的隐私信息,还是只是巧合。
白盒窃取
白盒窃取攻击对目标模型具有完全访问权限,可以获得模型结构和参数,并基于此从目标模型中窃取训练数据。在这种情况下,攻击者往往利用梯度信息 进行数据窃取,因此此类攻击也被称为梯度逆向攻击 (gradient
inversion attack)。
由于联邦学习在设计上需要各方共享模型参数或梯度信息,这使其更容易遭受白盒数据窃取攻击 。实际上,白盒数据窃取攻击也大都以联邦学习范式为主要攻击目标。根据优化目标的不同,梯度逆向攻击可以分为两类:迭代梯度逆向 (iterative
gradient inversion)和递归梯度逆向 (recursive gradient
inversion)。迭代梯度逆向攻击通过迭代来步步缩小生成梯度与真实梯度(各方共享梯度)之间的差异;而递归梯度逆向攻击则对神经网络从后往前逐层递归优化,得到每层的最优输入。
迭代梯度逆向攻击
image-20250812180307434
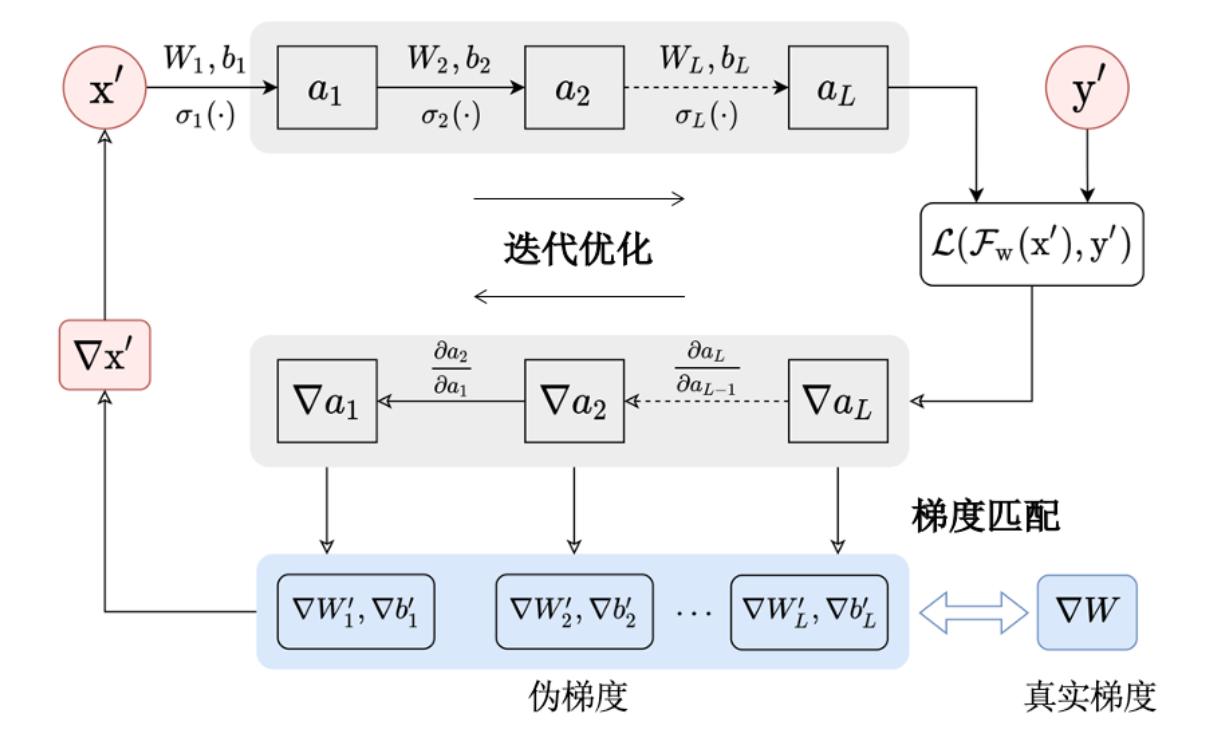
深度梯度泄露 (deep leakage from gradients,DLG)攻击
主要包括三个部分:伪数据初始化、梯度求导和梯度匹配。
攻击者首先初始化一个随机样本伪梯度
(说实话,公式有点没看懂)
IDLG 的作者发现,对于使用交叉熵损失函数(分类任务中最常用的损失函数)的模型,梯度的符号本身就泄露了真实的标签信息 。攻击者不再需要去“猜”标签,而是可以通过一个简单的解析步骤,100%准确地从梯度中直接计算出真实标签 。
特性
DLG (Deep Leakage from Gradients)
IDLG (Improved DLG)
核心思想
通过梯度匹配,同时优化假数据和假标签来恢复原始数据
先从梯度中精确解析出真实标签,再进行梯度匹配来恢复原始数据
标签恢复
随机猜测**,不稳定,是主要的性能瓶颈
确定性计算,可以100%准确地恢复标签(针对特定损失函数)
优化过程
同时优化数据和标签,复杂且不稳定
只优化数据,过程更简单、稳定
攻击效率
较低,需要更多迭代次数,容易失败
高,收敛速度快,成功率极高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 import torchimport torch.nn as nnimport torch.nn.functional as Fimport torchvision.transforms as transformsimport pickleimport osfrom PIL import Imageclass LeNet (nn.Module): def __init__ (self, channel=3 , hideen=768 , num_classes=36 ): super (LeNet, self ).__init__() act = nn.Sigmoid self .body = nn.Sequential( nn.Conv2d(channel, 12 , kernel_size=5 , padding=5 // 2 , stride=2 ), act(), nn.Conv2d(12 , 12 , kernel_size=5 , padding=5 // 2 , stride=2 ), act(), nn.Conv2d(12 , 12 , kernel_size=5 , padding=5 // 2 , stride=1 ), act(), ) self .fc = nn.Sequential( nn.Linear(hideen, num_classes) ) def forward (self, x ): out = self .body(x) out = out.view(out.size(0 ), -1 ) out = self .fc(out) return out def weights_init (m ): if hasattr (m, "weight" ): m.weight.data.uniform_(-0.5 , 0.5 ) if hasattr (m, "bias" ): m.bias.data.uniform_(-0.5 , 0.5 ) if __name__ == "__main__" : device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) print (f"🚀 Using device: {device} " ) lr = 0.1 max_iterations = 500 convergence_threshold = 1e-5 dic = "0123456789qwertyuiopasdfghjklzxcvbnm" flag = "" if not os.path.exists("recovered_images" ): os.makedirs("recovered_images" ) print ("开始进行iDLG攻击..." ) for i in range (20 ): torch.manual_seed(114514 ) model = LeNet().to(device) model.apply(weights_init) model.eval () gradient_path = f"data/flag_{i} .pkl" with open (gradient_path, 'rb' ) as f: original_dy_dx = [g.to(device) for g in pickle.load(f)] last_fc_bias_grad = original_dy_dx[-1 ] recovered_label_index = torch.argmin(last_fc_bias_grad).item() recovered_char = dic[recovered_label_index] flag += recovered_char print (f"[*] 攻击第 {i + 1 } /20 个梯度... ✅ 标签恢复成功: {recovered_char} (索引: {recovered_label_index} )" ) gt_label = torch.tensor([recovered_label_index]).long().to(device) dummy_data = torch.randn(1 , 3 , 32 , 32 ).to(device).requires_grad_(True ) optimizer = torch.optim.Adam([dummy_data], lr=lr) criterion = nn.CrossEntropyLoss().to(device) for it in range (max_iterations): optimizer.zero_grad() pred = model(dummy_data) dummy_loss = criterion(pred, gt_label) dummy_dy_dx = torch.autograd.grad(dummy_loss, model.parameters(), create_graph=True ) grad_diff = 0 for gx, gy in zip (dummy_dy_dx, original_dy_dx): grad_diff += ((gx - gy) ** 2 ).sum () grad_diff.backward() optimizer.step() if (it + 1 ) % 100 == 0 : print (f" 迭代 {it + 1 } /{max_iterations} , 梯度差异损失: {grad_diff.item():.4 e} " ) if grad_diff.item() < convergence_threshold: print (f" ✅ 梯度差异已收敛至 {grad_diff.item():.4 e} (在 {it + 1 } 次迭代后), 提前停止。" ) break else : print (f" ⚠️ 已达到最大迭代次数 {max_iterations} ,但损失仍为 {grad_diff.item():.4 e} 。" ) recovered_image = transforms.ToPILImage()(dummy_data.squeeze(0 ).cpu()) recovered_image.save(f"recovered_images/flag_{i} _{recovered_char} .png" ) print ("\n-------------------------------------------------" ) print (f"🎉 攻击完成!恢复的Flag是: {flag} " ) print ("-------------------------------------------------" )
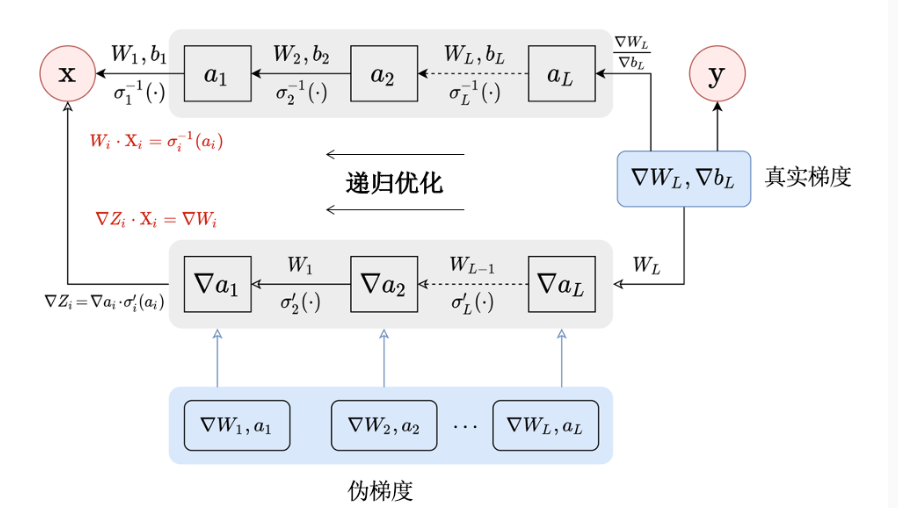
递归梯度逆向攻击
image-20250812181206981
递归梯度逆向攻击是通过真实梯度来反向推断神经网络每一层的输入,一直到输入层。最简单的情况是每一层都是一个感知器(perceptron)。
当损失是均方差损失函数时,感知器的某一维的输入可以直接通过当前感知器的梯度逆向得到:
其中,递归梯度逆向攻击目前只被证实能作用于卷积层和全连接层,而无法应用在池化层 (pooling
layer)和跳跃连接 (skip
connection)。 此外,递归梯度逆向攻击也不能很好地还原批次数据。